Introducción: El Mapa de Memoria de un Programa¶
Todas las variables y el código de un programa residen en la memoria. Cuando un programa se ejecuta, el sistema operativo le asigna un espacio de direcciones virtuales que se organiza en secciones específicas, cada una con un propósito diferente. Esta organización permite al sistema gestionar eficientemente los recursos y aislar las distintas necesidades de almacenamiento.
Estado de un Programa¶
//? Integrar a este apunte.
El estado de un programa (del inglés, program state) en un instante de tiempo es la colección completa y precisa de toda la información mutable que define al programa en ese momento. Es una instantánea (snapshot) que, si se pudiera capturar y restaurar, permitiría que la ejecución del programa continuara desde ese punto exacto sin ninguna diferencia observable.
Comprender el estado es fundamental para el debugging, la concurrencia y el análisis del comportamiento del programa. Se compone de varios elementos distribuidos en la memoria y en los registros del procesador.
Componentes Principales del Estado¶
El estado de un programa en C se almacena principalmente en las siguientes áreas de memoria y registros de la CPU:
1. La Pila (Stack)¶
Es una región de memoria gestionada por el compilador bajo un modelo LIFO (Last-In, First-Out). Cada vez que se invoca una función, se crea un nuevo marco de pila (stack frame) que se apila sobre el anterior.
El stack frame de una función contiene:
Variables locales: Todas las variables declaradas dentro del ámbito de la función que no son estáticas.
Parámetros de la función: Las copias de los argumentos pasados a la función.
Dirección de retorno: La dirección de la instrucción en el código a la que el programa debe volver cuando la función actual finalice.
Información de estado de la pila anterior: Un puntero al stack frame de la función que la llamó (el llamador o caller).
El estado en la pila es volátil y efímero; se crea al entrar en una función y se destruye al salir de ella.
2. El Montículo (Heap)¶
Es una región de memoria para la asignación dinámica. A diferencia de la
pila, su gestión es explícita y responsabilidad del programador mediante el uso
de funciones de la biblioteca estándar como malloc(), calloc(), realloc()
y free().
El estado en el montículo incluye todos los bloques de memoria reservados que no
han sido liberados. El acceso a estos bloques se realiza a través de punteros,
los cuales pueden residir en la pila, en el segmento de datos, o incluso en otro
bloque del propio montículo. La gestión incorrecta del heap (e.g., no liberar
memoria con free()) conduce a fugas de memoria (memory leaks).
3. Segmentos de Datos Estáticos¶
Estas áreas de memoria se asignan cuando el programa se carga y persisten durante toda su ejecución. Se dividen principalmente en dos:
Segmento
.data: Contiene las variables globales y estáticas que son explícitamente inicializadas por el programador. Por ejemplo:int contador_global = 10;.Segmento
.bss(Block Started by Symbol): Contiene las variables globales y estáticas que no son inicializadas explícitamente. El sistema operativo se encarga de inicializar esta memoria a cero antes de que comience la ejecución del programa. Por ejemplo:static int buffer_interno;.
El contenido de estas variables forma una parte persistente del estado del programa.
4. Contexto de Ejecución (CPU)¶
El estado no reside únicamente en la memoria RAM, sino también en los registros internos de la CPU.
Contador de Programa (Program Counter - PC): Es el registro más crítico. Contiene la dirección de memoria de la próxima instrucción que se va a ejecutar. Su valor define el punto exacto de la ejecución dentro del segmento de código (
.text).Registros de Propósito General: Almacenan operandos y resultados intermedios de operaciones aritméticas, lógicas y de transferencia de datos. El contenido de estos registros es una parte muy volátil pero esencial del estado en un instante preciso.
5. Estado Externo¶
Un programa interactúa con el sistema operativo y otros sistemas. Este estado incluye:
Descriptores de archivo (File Descriptors): Enteros que representan archivos abiertos, sockets de red, pipes, etc. El estado incluye qué archivos están abiertos y la posición actual del cursor de lectura/escritura en cada uno.
Buffers de E/S (I/O Buffers): Datos que han sido escritos por el programa pero aún no han sido vaciados (flushed) al disco o a la red, y viceversa.
Ejemplo Práctico Detallado¶
Analicemos el estado en un punto específico del siguiente programa en C:
#include <stdio.h>
#include <stdlib.h>
int accesos_totales = 0; // Segmento .data (inicializado)
char* puntero_global; // Segmento .bss (no inicializado, será NULL)
void procesar(int factor) {
int i; // En la pila (stack)
for (i = 0; i < factor; i++) {
accesos_totales++;
}
char* buffer_local = malloc(10 * sizeof(char)); // Puntero 'buffer_local' en la pila.
// El bloque de 10 bytes está en el montículo (heap).
// PUNTO DE ANÁLISIS DEL ESTADO
sprintf(buffer_local, "Hola");
puntero_global = buffer_local;
}
int main() {
procesar(5);
printf("%s\n", puntero_global);
free(puntero_global); // Liberamos la memoria del montículo.
return 0;
}Snapshot del Estado en el “PUNTO DE ANÁLISIS” (dentro de
procesar):Pila (Stack):
Marco de
main(): (En la base de la pila, más abajo) Contiene su propia información, incluyendo la dirección de retorno después de la llamada aprocesar().Marco de
procesar(): (En la cima de la pila)Parámetro
factor: su valor es5.Variable local
i: su valor es5(valor final tras el lazofor).Variable local
buffer_local: es un puntero. Contiene la dirección de memoria del primer byte del bloque de 10 bytes quemallocasignó en el montículo.Dirección de retorno: apunta a la instrucción
printfenmain.
Montículo (Heap):
Existe un bloque de 10 bytes de memoria reservada. La dirección de este bloque es el valor almacenado en
buffer_local. Justo antes desprintf, su contenido es indeterminado. Justo después, sus primeros 5 bytes contendrán los caracteres'H','o','l','a','\0'.
Segmento de Datos:
.data: La variableaccesos_totalestiene el valor5..bss: La variablepuntero_globaltodavía tiene su valor inicialNULL(cero), ya que la asignaciónpuntero_global = buffer_local;aún no se ha ejecutado.
Contexto de la CPU:
Contador de Programa (PC): Apunta a la dirección de memoria de la instrucción correspondiente a la línea
sprintf(buffer_local, "Hola");.Registros: Contendrán valores intermedios. Por ejemplo, un registro probablemente contenga la dirección de
buffer_localy otro la dirección de la cadena literal"Hola", listos para ser usados como argumentos parasprintf.
Transiciones de Estado¶
El programa es una máquina que transita de un estado a otro. Cada instrucción ejecutada modifica el estado:
Una asignación (
x = 10;) modifica la memoria donde residex.Una llamada a función (
procesar(5);) crea un nuevo marco en la pila y cambia elPC.Un
returndestruye el marco de pila actual y restaura elPCa la dirección de retorno.malloc()modifica el estado del montículo.Una operación de E/S (
printf()) puede modificar un buffer interno y eventualmente el estado de un dispositivo externo (la consola).
Dominar el concepto de estado es pasar de “escribir código que funciona” a “entender por qué y cómo funciona”, lo cual es indispensable para la programación de sistemas de bajo nivel.
De acuerdo. A continuación, una ampliación del concepto que generaliza la idea de estado más allá de su implementación técnica en C, enfocándose en su rol como información unificada.
Ampliación: El Estado como Información y Potencialidad¶
Si nos abstraemos de la implementación física (pila, montículo, registros), podemos entender el estado del programa desde una perspectiva teórica más amplia, como un concepto de la teoría de la información y de los sistemas dinámicos.
El Programa como una Trayectoria en un Espacio de Estados¶
Imaginemos un vasto universo multidimensional donde cada punto representa un único estado posible que el programa podría adoptar. Este universo es el Espacio de Estados (State Space) del programa. Cada variable, cada byte en el montículo, cada registro de la CPU, es una dimensión de este espacio.
La ejecución de un programa no es más que una trayectoria o un camino a través de este espacio. Cada instrucción de la CPU es un pequeño paso que mueve al programa de un punto (estado ) a otro punto muy cercano (estado ).
Punto de Origen: El estado inicial del programa (variables globales en cero o sus valores iniciales, pila vacía excepto por el marco de
main, etc.).Trayectoria: La secuencia de estados por los que pasa el programa.
Punto Final: El estado terminal, cuando
mainretorna o se invocaexit().
Desde esta óptica, el estado en su conjunto es la coordenada exacta del programa dentro de su universo de posibilidades en un instante dado.
Determinismo y la Flecha del Tiempo del Programa¶
Un sistema es determinista si su estado futuro está completamente
determinado por su estado actual y sus entradas. Gran parte de un programa en C
es determinista: si el estado en es conocido, el resultado de x = y + z;
es predecible y llevará a un único estado .
Sin embargo, los programas interactúan con el exterior, introduciendo no-determinismo. El estado del programa se ve afectado por eventos cuyo tiempo y contenido no están bajo el control del código:
Entrada del usuario: El próximo estado depende de qué tecla se presione y cuándo.
Concurrencia: La intercalación de hilos (thread scheduling) por el sistema operativo es no-determinista. Dos ejecuciones idénticas pueden tener trayectorias diferentes en el espacio de estados.
Datos de red o archivos: El contenido recibido de un socket o leído de un disco.
El estado, por lo tanto, es el registro de la historia única de la trayectoria del programa, incluyendo cómo resolvió las bifurcaciones no-deterministas que encontró.
El Estado como Información y Potencialidad¶
En su nivel más fundamental, el estado es la encarnación de la información que el programa ha acumulado. Es su memoria. Contiene todo lo que el programa “sabe” sobre su ejecución pasada y sobre las interacciones con su entorno.
Pero más importante aún, el estado define la potencialidad del programa. El estado actual no solo describe el “ahora”, sino que restringe drásticamente el conjunto de estados futuros posibles.
Si un puntero en el estado es
NULL, cualquier trayectoria futura que intente desreferenciarlo es inválida (resultará en un segmentation fault). El estadopuntero = NULLelimina una vasta cantidad de futuros posibles.Si una variable
autenticadoesfalse, las ramas del código que requieren autenticación son inaccesibles. La trayectoria del programa está constreñida a otras partes del espacio de estados.
En resumen, la detallada distribución del estado en la pila, el montículo y los
registros es el sustrato físico donde se almacena esta información
abstracta. El estado en su conjunto es lo que da identidad y continuidad al
proceso en ejecución, diferenciándolo del código estático y muerto (.text)
del cual se originó. Es la suma de su memoria y la definición de su potencial
futuro.
Memoria Virtual: La Abstracción Fundamental¶
Es crucial comprender que la memoria que ves desde tu programa no es la memoria física (RAM) directamente. El sistema operativo, en colaboración con el procesador, implementa un sistema de memoria virtual que proporciona a cada proceso su propio espacio de direcciones aislado.
¿Qué es la memoria virtual?
La memoria virtual es una capa de abstracción que mapea direcciones virtuales (las que usa tu programa) a direcciones físicas (las ubicaciones reales en la RAM). Este mapeo se realiza mediante una estructura de datos llamada tabla de páginas (page table) que el hardware del procesador consulta en cada acceso a memoria.
Ventajas de la memoria virtual:
Aislamiento entre procesos: Cada proceso tiene su propio espacio de direcciones. Un proceso no puede acceder (accidentalmente o maliciosamente) a la memoria de otro proceso.
Uso eficiente de la RAM: La memoria física puede ser compartida entre múltiples procesos de forma transparente. Páginas que no se usan pueden moverse al disco (swap).
Direcciones consistentes: Tu programa puede usar siempre las mismas direcciones virtuales, independientemente de dónde esté físicamente ubicado el proceso en la RAM.
Más memoria de la que existe físicamente: Mediante el uso de swap (intercambio con disco), el sistema operativo puede simular más memoria RAM de la que realmente tiene la computadora.
Páginas de memoria:
La memoria se divide en bloques de tamaño fijo llamados páginas (típicamente 4 KB en sistemas x86/x86_64). El sistema operativo gestiona la memoria en unidades de páginas, no bytes individuales. Cuando tu programa solicita memoria, el sistema operativo asigna páginas completas, aunque solo uses una porción de ellas.

Figure 1:Proceso de traducción de direcciones virtuales a físicas mediante la MMU (Memory Management Unit) y la tabla de páginas.
Segmentación de la Memoria¶
Un programa en ejecución divide su espacio de memoria en las siguientes áreas:
.text (Código) : Almacena el código ejecutable del programa, es decir, las instrucciones que ejecuta la CPU. Este segmento es de solo lectura para prevenir modificaciones accidentales o maliciosas del código durante la ejecución.
.rodata (Datos de solo lectura) : Contiene datos constantes y literales de cadena, como "Hola, mundo". Al igual que .text, este segmento es de solo lectura.
.data (Datos inicializados) : Almacena variables globales y estáticas que han sido explícitamente inicializadas en el código fuente.
.bss (Block Started by Symbol) : Contiene variables globales y estáticas (static). Que deben ser inicializadas, pero el sistema operativo
les dará un valore en cero al cargar el programa.
La palabra clave extern¶
La palabra clave extern se utiliza para declarar una variable global que está definida en otro archivo fuente. No crea una variable, sino que le dice al compilador: “Esta variable existe en otro lugar, confía en mí. El enlazador (linker) se encargará de encontrarla”.
Ejemplo:
archivo1.c
#include <stdio.h>
// Definición de la variable global
int contador_global = 42;
void imprimir_contador(); // Prototipo de la función en archivo2.c
int main() {
imprimir_contador();
return 0;
}archivo2.c
#include <stdio.h>
// Declaración de la variable externa
extern int contador_global;
void imprimir_contador() {
printf("El contador global es: %d\n", contador_global);
}Al compilar y enlazar ambos archivos (gcc archivo1.c archivo2.c -o programa), el enlazador resolverá la referencia a contador_global en archivo2.c con la definición en archivo1.c.
Si las variables globales tenian problemas, las variables globales compartidas
entre varios archivos son aún mas problemáticas, ver Regla 0x2004h: No se permite el uso de variables globales.
Heap (Montón) : Zona de memoria destinada a la asignación dinámica. Crece desde direcciones bajas hacia direcciones altas. Su gestión es responsabilidad del programador.
Stack (Pila) : Zona de memoria para variables locales y gestión de llamadas a funciones. Crece desde direcciones altas hacia direcciones bajas. Su gestión es automática.
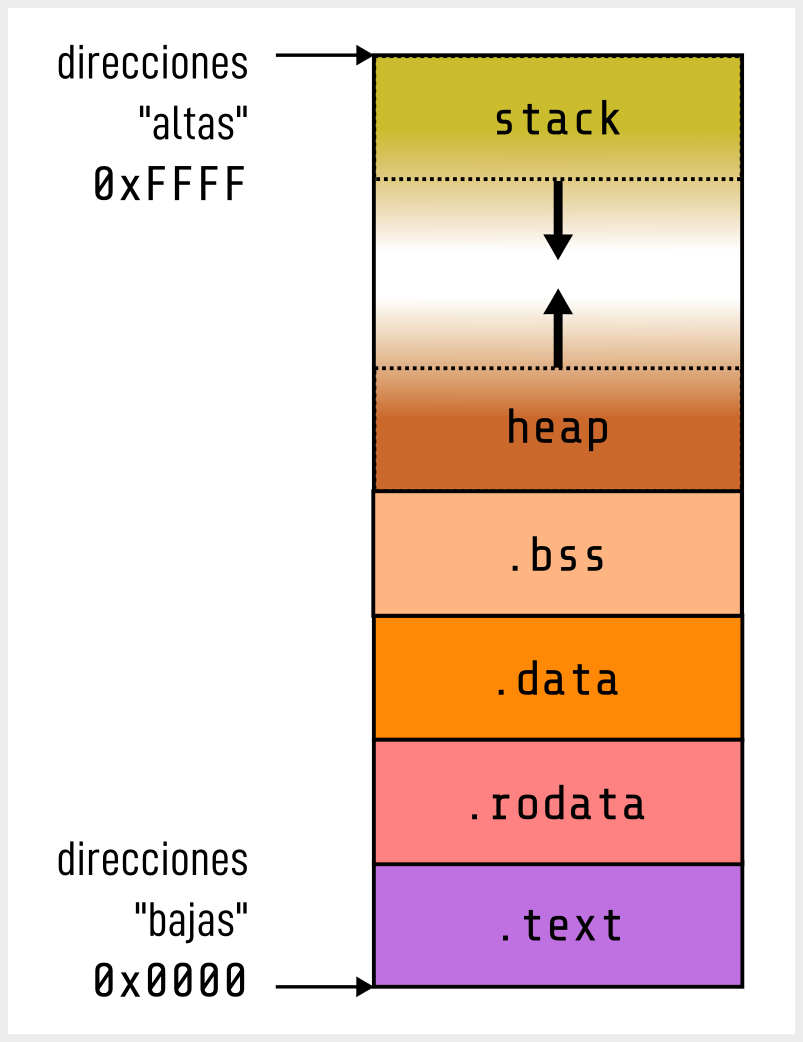
Figure 2:Organización típica de la memoria de un proceso en sistemas Unix/Linux.
La Pila (Stack)¶
La pila es una estructura de datos fundamental en la ejecución de programas. Su nombre proviene de la analogía con una pila de platos: el último elemento añadido es el primero en ser retirado.
Funcionamiento¶
La pila opera bajo el principio LIFO (Last-In, First-Out): el último elemento que entra es el primero en salir, similar a una pila de platos donde solo podés tomar el plato superior. Cada vez que llamás a una función, el sistema reserva un nuevo marco de pila (stack frame) que contiene las variables locales, los parámetros y la dirección de retorno. Cuando la función termina, ese marco se libera automáticamente.
Este mecanismo automático es extremadamente eficiente porque simplemente implica mover un puntero (el stack pointer) que indica la cima de la pila. Al entrar a una función, el puntero se mueve hacia abajo para hacer espacio; al salir, se mueve hacia arriba, “liberando” el espacio sin necesidad de limpiarlo explícitamente.
Ejemplo conceptual:
void funcion_b()
{
int z = 30;
// Stack: [x=10] [y=20] [z=30] <- cima
// Al retornar, z desaparece automáticamente
}
void funcion_a()
{
int y = 20;
// Stack: [x=10] [y=20] <- cima
funcion_b();
// Stack: [x=10] [y=20] <- cima (z ya no existe)
}
int main()
{
int x = 10;
// Stack: [x=10] <- cima
funcion_a();
// Stack: [x=10] <- cima (y ya no existe)
return 0;
}Anatomía de un Stack Frame¶
Cada llamada a función crea un stack frame (marco de pila) que contiene toda la información necesaria para ejecutar esa función y retornar correctamente. Comprender la estructura de un stack frame es fundamental para entender cómo funcionan las llamadas a funciones y por qué ciertos errores ocurren.
Estructura típica de un stack frame:

Figure 3:Estructura detallada de un stack frame mostrando la organización de parámetros, dirección de retorno, base pointer, variables locales y temporales.
Registros clave involucrados:
Stack Pointer (SP): Apunta siempre a la cima del stack. Se mueve con cada
pushandpop. En x86-64, se mapea al registrorsp.Base Pointer (BP o Frame Pointer): Apunta a la base del frame actual. Permite acceder a parámetros y variables locales con offsets fijos. En x86-64, se mapea al registro
rbp.
Secuencia de una llamada a función:
Preparación (caller):
Los argumentos se colocan en el stack (o registros, según la convención).
Se ejecuta la instrucción
CALL, que:Guarda la dirección de retorno en el stack
Salta a la dirección de la función
Prólogo (callee):
Se guarda el Base Pointer anterior
El Base Pointer actual se establece al Stack Pointer
Se reserva espacio para variables locales (se decrementa el SP)
Ejecución:
El cuerpo de la función se ejecuta
Las variables locales se acceden mediante offsets desde el BP
Epílogo (callee):
Se restaura el Stack Pointer al Base Pointer
Se restaura el Base Pointer anterior
Se ejecuta
RETURN, que:Extrae la dirección de retorno del stack
Salta a esa dirección
Limpieza (caller):
Se limpia el espacio usado para argumentos (según la convención)
(El funcionamiento detallado en código ensamblador y a nivel de registros se explica en la sección de la sección de ensamblador al final de este capítulo al final de este capítulo).
Contenido del Stack¶
La pila almacena:
Variables locales de funciones.
Parámetros pasados a las funciones.
Direcciones de retorno que indican dónde debe continuar la ejecución después de que una función termine.
Información de estado del procesador (registros salvados).
Ventajas y Desventajas¶
Ventajas:
Acceso extremadamente rápido a las variables.
Gestión automática: no hay riesgo de fugas de memoria.
La localidad de referencia mejora el rendimiento del caché.
Desventajas:
Tamaño limitado y fijo (típicamente entre 1 MB y 8 MB en sistemas modernos).
No es posible cambiar el tamaño de las variables en tiempo de ejecución.
Las variables solo existen dentro de su ámbito léxico (scope).
Riesgo de stack overflow si se realizan llamadas recursivas profundas o se declaran arreglos muy grandes.
Ejemplo del error común:
int *funcion_incorrecta()
{
int valor = 42;
return &valor; // ERROR: retorna dirección de variable local
// 'valor' desaparece al salir de la función
}
int *funcion_correcta()
{
int *valor = malloc(sizeof(*valor));
if (valor == NULL)
{
return NULL;
}
*valor = 42;
return valor; // CORRECTO: la memoria persiste
// El llamador debe liberar esta memoria
}El Montón (Heap)¶
El heap es una región de memoria diseñada para la asignación dinámica. A diferencia de la pila, el heap permite solicitar memoria en tiempo de ejecución y mantenerla disponible hasta que explícitamente decidás liberarla.
Concepto¶
El heap puede visualizarse como una gran “reserva” de memoria disponible para el programa. Cuando necesitás un bloque de memoria de tamaño variable o que persista más allá del alcance de una función, recurrís al heap mediante funciones especializadas de asignación de memoria.
A diferencia del stack, donde el compilador y el sistema operativo gestionan automáticamente la creación y destrucción de variables, en el heap el programador tiene control total: decidís cuándo solicitar memoria y cuándo devolverla al sistema. Esta flexibilidad otorga un poder considerable, pero también impone una gran responsabilidad.
¿Cuándo usar el heap?
Usá el heap cuando:
No conocés el tamaño de los datos en tiempo de compilación.
Los datos deben persistir después de que la función que los creó retorne.
Necesitás grandes cantidades de memoria que excederían el tamaño limitado del stack.
Querés crear estructuras de datos complejas como listas enlazadas, árboles o grafos.
¿Cuándo usar el stack?
Usá el stack cuando:
El tamaño de los datos es conocido en tiempo de compilación y es pequeño.
Los datos solo son necesarios dentro del ámbito de la función actual.
Querés la máxima eficiencia de acceso a memoria.
Ventajas y Desventajas¶
Ventajas:
Flexibilidad total: podés solicitar la cantidad exacta de memoria que necesitás en tiempo de ejecución.
Persistencia: la memoria permanece válida hasta que la liberás explícitamente con
free.Tamaño mayor: el límite depende de la memoria disponible en el sistema, no de un tamaño de pila fijo.
Desventajas:
Acceso más lento que el stack debido a la indirección y la fragmentación.
Requiere gestión manual, lo que introduce riesgos de errores como fugas de memoria (memory leaks) y accesos inválidos.
Fragmentación de memoria a lo largo del tiempo.
Posibilidad de errores sutiles difíciles de detectar: accesos después de liberar memoria, dobles liberaciones, pérdida de referencias.
Comparación Stack vs Heap¶
La siguiente tabla resume las diferencias clave entre el stack y el heap para ayudarte a decidir cuál usar en cada situación:
Table 1:Comparación entre Stack y Heap
| Característica | Stack | Heap |
|---|---|---|
| Gestión | Automática | Manual |
| Velocidad | Muy rápida (ciclos de CPU) | Más lenta (acceso a RAM indirecto) |
| Tamaño | Limitado (1-8 MB típico) | Grande (limitado por RAM) |
| Tamaño en tiempo de compilación | Debe ser conocido | Puede ser dinámico |
| Persistencia | Solo dentro de la función | Hasta que se libere |
| Fragmentación | No ocurre | Puede ocurrir |
| Riesgo de errores | Bajo (overflow) | Alto (leaks, punteros colgantes) |
| Uso típico | Variables locales pequeñas | Estructuras grandes o dinámicas |
Regla práctica: Usá el stack siempre que puedas (por velocidad y simplicidad), y recurrí al heap solo cuando sea necesario (por flexibilidad).
Jerarquía de Memoria y Caché¶
Para comprender completamente por qué el stack es más rápido que el heap, necesitás entender la jerarquía de memoria del hardware moderno. La memoria no es un espacio uniforme: hay múltiples niveles con diferentes velocidades y tamaños.
La jerarquía típica (de más rápido a más lento):

Figure 4:Jerarquía de memoria desde los registros CPU (más rápidos) hasta los discos duros (más lentos), mostrando la relación inversa entre velocidad y capacidad.
Principio de localidad:
El hardware moderno optimiza para dos tipos de localidad:
Localidad temporal: Si accedés a un dato ahora, es probable que lo accedas de nuevo pronto.
Localidad espacial: Si accedés a un dato, es probable que accedas a datos cercanos en memoria pronto.
Cómo funcionan los cachés:
Cuando el CPU necesita leer memoria, primero busca en el caché L1. Si no está (cache miss), busca en L2, luego L3, y finalmente en RAM. Cuando encuentra el dato, también trae a caché los bytes circundantes (una “línea de caché”, típicamente 64 bytes).
Acceso a memoria:
CPU → L1? (hit) → Usar dato (rápido)
↓ (miss)
L2? (hit) → Copiar a L1 → Usar dato
↓ (miss)
L3? (hit) → Copiar a L2 y L1 → Usar dato
↓ (miss)
RAM → Copiar a cachés → Usar dato (lento)Por qué el stack es más rápido:
Alta localidad temporal: Las variables locales se usan frecuentemente en un corto período (dentro de la función). Probablemente permanecen en caché.
Alta localidad espacial: Las variables locales están físicamente juntas en memoria. Acceder a una trae las otras al caché automáticamente.
Patrón predecible: El stack crece y decrece de forma predecible, lo que permite al hardware pre-cargar datos.
Acceso secuencial: Generalmente accedés a variables locales en orden, lo que maximiza el uso de las líneas de caché.
Por qué el heap es más lento:
Menor localidad: Las asignaciones de memoria pueden estar dispersas por todo el heap, causando más cache misses.
Indirección: Acceder a memoria del heap requiere desreferenciar punteros, agregando un nivel de indirección.
Fragmentación: Los bloques fragmentados están físicamente separados, reduciendo la localidad espacial.
Overhead del allocator: Cada
malloc/freeinvolucra algoritmos de búsqueda y mantenimiento de estructuras de datos.
Ejemplo cuantitativo:
// Versión stack (rápida):
void procesar_stack()
{
int datos[1000]; // Asignación instantánea
// Todos los elementos probablemente en caché:
for (int i = 0; i < 1000; i++)
{
datos[i] = i * 2; // Acceso secuencial, alta localidad
}
}
// Versión heap (más lenta):
void procesar_heap()
{
int *datos = malloc(1000 * sizeof(int)); // Llamada a función
if (datos == NULL) return;
// Posiblemente más cache misses:
for (int i = 0; i < 1000; i++)
{
datos[i] = i * 2; // Menos predecible para el hardware
}
free(datos); // Otra llamada a función
}En un benchmark real, la versión stack podría ser 2-5 veces más rápida, especialmente para arreglos pequeños que caben completamente en caché.
Modelo de Costos: Cuantificando el Rendimiento¶
Comprender el costo relativo de las operaciones de memoria permite tomar decisiones informadas sobre diseño y optimización. Este modelo proporciona una intuición sobre el rendimiento relativo.
Costos relativos (ciclos de CPU aproximados):
Si un acceso a registro tomara 1 segundo, acceder a RAM tomaría entre 2 y 5 minutos, y leer del disco duro tomaría 4 meses. Esta escala ayuda a visualizar la enorme diferencia de velocidades.
| Operación | Ciclos aprox. | Equivalente temporal |
|---|---|---|
| Acceso a registro | 1 | 1 segundo |
| Acceso a L1 cache | 4 | 4 segundos |
| Acceso a L2 cache | 12 | 12 segundos |
| Acceso a L3 cache | 40 | 40 segundos |
| Acceso a RAM | 100-300 | 2-5 minutos |
| malloc pequeño (heap hit) | 50-100 | 1-2 minutos |
| malloc grande (new pages) | 1,000-10,000 | 15 minutos - 3 horas |
| free (simple) | 20-50 | 20-50 segundos |
| Fallo de página (page fault) | 10,000-100,000 | 3 horas - 1 día |
| Acceso a SSD | 100,000 | 1 día |
| Acceso a disco HDD | 10,000,000 | 4 meses |
Implicaciones prácticas:
1. Las asignaciones no son gratuitas:
// Ineficiente: muchas asignaciones pequeñas
for (int i = 0; i < 1000; i++)
{
char *str = malloc(10); // 1000 llamadas a malloc
// ... usar str ...
free(str); // 1000 llamadas a free
}
// Mejor: una asignación grande
char *buffer = malloc(10000);
for (int i = 0; i < 1000; i++)
{
char *str = buffer + (i * 10); // Solo aritmética de punteros
// ... usar str ...
}
free(buffer); // Una sola llamada a freeHerramienta Clave: Punteros¶
Los punteros son el mecanismo fundamental que permite trabajar con memoria dinámica en C. Un puntero no almacena un valor directo, sino la dirección de memoria donde se encuentra ese valor.
El Puntero void *: Puntero Genérico¶
Un void * es un puntero especial que puede apuntar a cualquier tipo de dato. No tiene asociado un tipo específico, por lo que:
No puede ser desreferenciado directamente.
No se puede hacer aritmética con él (no sabe el tamaño del tipo).
Puede convertirse implícitamente a cualquier otro tipo de puntero.
Uso principal:
Las funciones de memoria como malloc retornan void * porque no saben qué tipo de dato vas a almacenar:
void *memoria_generica = malloc(100); // void *, no sabemos qué tipo
int *enteros = memoria_generica; // Conversión implícita a int *
char *caracteres = memoria_generica; // O a char *, según necesitesLimitaciones:
void *ptr = malloc(10 * sizeof(int));
// ERROR: No se puede desreferenciar void *
// *ptr = 42;
// CORRECTO: Convertir primero
int *int_ptr = (int *)ptr;
*int_ptr = 42;
// ERROR: No se puede hacer aritmética con void *
// ptr = ptr + 1; // ¿Cuántos bytes avanzar?
// CORRECTO: Convertir a tipo concreto primero
int_ptr = int_ptr + 1; // Avanza sizeof(int) bytesCasteos Avanzados de Punteros¶
Los casteos de punteros en C son una herramienta poderosa pero peligrosa. Comprender los casteos avanzados, especialmente los punteros a arrays, es esencial para trabajar con memoria dinámica multidimensional y estructuras de datos complejas.
Casteos Básicos entre Tipos de Punteros¶
El casteo más simple convierte un puntero de un tipo a otro:
int *int_ptr = malloc(sizeof(int));
char *char_ptr = (char *)int_ptr; // Cast explícito
// Reinterpretar los bytes:
*int_ptr = 0x41424344;
printf("%c\n", char_ptr[0]); // Imprime 'D' (little-endian)Punteros a Punteros y Arrays Dinámicos 2D¶
Un patrón común es usar punteros a punteros para crear arrays bidimensionales dinámicos:
// Array 2D: 3 filas, 4 columnas
int **matriz = malloc(3 * sizeof(int *));
for (int i = 0; i < 3; i++)
{
matriz[i] = malloc(4 * sizeof(int));
}
// Acceso: matriz[fila][columna]
matriz[0][0] = 10;
matriz[2][3] = 99;
// Liberar: en orden inverso
for (int i = 0; i < 3; i++)
{
free(matriz[i]);
}
free(matriz);Visualización en memoria:

Figure 5:Estructura de int **matriz mostrando un array de punteros donde cada puntero apunta a una fila diferente. Las filas están dispersas en memoria (no contiguas), lo que resulta en mala localidad de caché.
Desventaja: Las filas no están contiguas en memoria, lo que reduce la localidad del caché.
Puntero a Array: (*)[N]¶
Un puntero a array es fundamentalmente diferente de un puntero a puntero. Apunta a un array completo como una unidad, no a un elemento individual.
Sintaxis:
int (*ptr)[4]; // Puntero a array de 4 enterosLos paréntesis son cruciales:
int (*ptr)[4]→ Puntero a array de 4 intsint *ptr[4]→ Array de 4 punteros a int (¡completamente diferente!)
Uso principal: Trabajar con arrays 2D contiguos en memoria.
Ejemplo fundamental:
// Declaración de array 2D tradicional
int matriz[3][4] = {
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 10, 11, 12}
};
// Puntero a array de 4 enteros
int (*ptr)[4] = matriz;
// Acceso equivalente:
printf("%d\n", matriz[1][2]); // 7
printf("%d\n", ptr[1][2]); // 7
printf("%d\n", (*(ptr + 1))[2]); // 7 - explícito¿Qué significa int (*ptr)[4]?
ptres un punteroCuando desreferenciás
*ptr, obtenés un array de 4 enterosptr + 1avanzasizeof(int[4])bytes (16 bytes si int = 4 bytes)
Aritmética de punteros a array:
int (*ptr)[4] = matriz;
// ptr apunta a matriz[0] (toda la primera fila)
// ptr + 1 apunta a matriz[1] (toda la segunda fila)
// ptr + 2 apunta a matriz[2] (toda la tercera fila)
// Cada incremento salta 4 * sizeof(int) bytesArrays 2D Contiguos con Puntero Plano¶
La forma más portable, robusta y eficiente de representar una matriz dinámica contigua en memoria es mediante un puntero plano (int *) en el heap, realizando la indexación bidimensional manualmente a través de la fórmula matemática i * columnas + j:
#include <stdio.h>
#include <stdlib.h>
// Crear matriz 2D contigua: filas × columnas
int *crear_matriz_contigua(size_t filas, size_t columnas)
{
// Asignar toda la memoria en un solo bloque lineal
int *matriz = malloc(filas * columnas * sizeof(*matriz));
if (matriz == NULL)
{
return NULL;
}
// Inicializar a cero
for (size_t i = 0; i < filas * columnas; i++)
{
matriz[i] = 0;
}
return matriz;
}
int main()
{
size_t filas = 3;
size_t columnas = 4;
int *matriz = crear_matriz_contigua(filas, columnas);
if (matriz == NULL)
{
return 1;
}
// Llenar la matriz con cálculo manual de índice lineal (i * columnas + j)
for (size_t i = 0; i < filas; i++)
{
for (size_t j = 0; j < columnas; j++)
{
matriz[i * columnas + j] = (int)(i * columnas + j);
}
}
// Acceso manual: matriz[i * columnas + j]
printf("matriz[1][2] = %d\n", matriz[1 * columnas + 2]);
// Liberar: una sola llamada
free(matriz);
return 0;
}Visualización en memoria:
![Comparación entre puntero a puntero (int **) con filas dispersas y puntero a array (int (*)[N]) con datos contiguos. La disposición contigua mejora significativamente la localidad de caché.](/build/pointer_to_array-1a28674117ae55c727c4b7695a26f55c.svg)
Figure 6:Comparación entre puntero a puntero (int **) con filas dispersas y puntero a array (int (*)[N]) con datos contiguos. La disposición contigua mejora significativamente la localidad de caché.
Casteo a Puntero a Array¶
A veces necesitás reinterpretar memoria asignada como array multidimensional:
// Asignar memoria plana
int *memoria_plana = malloc(3 * 4 * sizeof(int));
// Reinterpretar como matriz 3×4
int (*matriz)[4] = (int (*)[4])memoria_plana;
// Ahora podés usar sintaxis de array 2D:
matriz[0][0] = 1;
matriz[1][2] = 7;
matriz[2][3] = 12;
// El acceso matriz[i][j] se traduce a:
// memoria_plana[i * 4 + j]Equivalencia:
// Estas tres formas son equivalentes:
matriz[i][j]
(*(matriz + i))[j]
memoria_plana[i * 4 + j]Ejemplo Completo: Múltiples Representaciones¶
#include <stdio.h>
#include <stdlib.h>
void imprimir_por_puntero_plano(int *arr, size_t filas, size_t cols)
{
printf("Como puntero plano:\n");
for (size_t i = 0; i < filas * cols; i++)
{
printf("%2d ", arr[i]);
if ((i + 1) % cols == 0) printf("\n");
}
}
void imprimir_por_puntero_a_array(int (*arr)[4], size_t filas)
{
printf("Como puntero a array:\n");
for (size_t i = 0; i < filas; i++)
{
for (size_t j = 0; j < 4; j++)
{
printf("%2d ", arr[i][j]);
}
printf("\n");
}
}
int main()
{
// Asignar memoria contígua para 3×4 enteros
int *memoria = malloc(3 * 4 * sizeof(int));
if (memoria == NULL)
{
return 1;
}
// Llenar con valores
for (int i = 0; i < 12; i++)
{
memoria[i] = i + 1;
}
// Representación 1: Puntero plano
imprimir_por_puntero_plano(memoria, 3, 4);
printf("\n");
// Representación 2: Casteo a puntero a array
int (*matriz)[4] = (int (*)[4])memoria;
imprimir_por_puntero_a_array(matriz, 3);
printf("\n");
// Acceso directo con ambas representaciones:
printf("memoria[5] = %d\n", memoria[5]); // 6
printf("matriz[1][1] = %d\n", matriz[1][1]); // 6 (mismo elemento)
// Modificar a través de matriz
matriz[2][3] = 99;
printf("memoria[11] = %d\n", memoria[11]); // 99 (cambio reflejado)
free(memoria);
return 0;
}Typedef para Simplificar¶
Los punteros a arrays pueden ser difíciles de leer. Los typedef ayudan:
// Sin typedef (difícil de leer):
int (*crear_matriz(size_t n))[10]
{
return malloc(n * sizeof(int[10]));
}
// Con typedef (más claro):
typedef int fila_t[10]; // fila_t es un array de 10 ints
fila_t *crear_matriz(size_t n)
{
return malloc(n * sizeof(fila_t));
}
// Uso:
fila_t *matriz = crear_matriz(5);
matriz[0][0] = 42; // Funciona igual
free(matriz);Otro ejemplo con struct:
typedef struct {
int datos[4];
} fila_estructurada_t;
// Más legible que int (*)[4]
fila_estructurada_t *matriz = malloc(3 * sizeof(*matriz));
matriz[0].datos[0] = 10;Limitaciones y Consideraciones¶
1. Compatibilidad con C99/C11:
El tamaño del array debe ser conocido en tiempo de compilación, o necesitás VLAs (Variable Length Arrays, C99):
// OK en C99+ con VLAs:
int (*crear(size_t cols))[cols]
{
return malloc(5 * sizeof(int[cols]));
}
// NO OK en C89:
// El compilador necesita conocer cols en compile-time2. Portabilidad:
VLAs en tipos de retorno no son universalmente soportados. Para máxima portabilidad:
// Usar typedef con tamaño fijo:
typedef int fila_fija_t[10];
fila_fija_t *crear(size_t filas)
{
return malloc(filas * sizeof(fila_fija_t));
}
// O usar void * y castear:
void *crear_generico(size_t filas, size_t cols)
{
return malloc(filas * cols * sizeof(int));
}3. Debugging:
Los punteros a arrays pueden ser confusos en debuggers. A veces es más claro usar puntero plano con acceso manual:
// Más fácil de debuggear:
int *arr = malloc(filas * cols * sizeof(int));
int elemento = arr[i * cols + j]; // Cálculo explícito