Introducción: El Mapa de Memoria de un Programa¶
Todas las variables y el código de un programa residen en la memoria. Cuando un programa se ejecuta, el sistema operativo le asigna un espacio de direcciones virtuales que se organiza en secciones específicas, cada una con un propósito diferente. Esta organización permite al sistema gestionar eficientemente los recursos y aislar las distintas necesidades de almacenamiento.
Memoria Virtual: La Abstracción Fundamental¶
Es crucial comprender que la memoria que ves desde tu programa no es la memoria física (RAM) directamente. El sistema operativo, en colaboración con el procesador, implementa un sistema de memoria virtual que proporciona a cada proceso su propio espacio de direcciones aislado.
¿Qué es la memoria virtual?
La memoria virtual es una capa de abstracción que mapea direcciones virtuales (las que usa tu programa) a direcciones físicas (las ubicaciones reales en la RAM). Este mapeo se realiza mediante una estructura de datos llamada tabla de páginas (page table) que el hardware del procesador consulta en cada acceso a memoria.
Ventajas de la memoria virtual:
Aislamiento entre procesos: Cada proceso tiene su propio espacio de direcciones. Un proceso no puede acceder (accidentalmente o maliciosamente) a la memoria de otro proceso.
Uso eficiente de la RAM: La memoria física puede ser compartida entre múltiples procesos de forma transparente. Páginas que no se usan pueden moverse al disco (swap).
Direcciones consistentes: Tu programa puede usar siempre las mismas direcciones virtuales, independientemente de dónde esté físicamente ubicado el proceso en la RAM.
Más memoria de la que existe físicamente: Mediante el uso de swap (intercambio con disco), el sistema operativo puede simular más memoria RAM de la que realmente tiene la computadora.
Páginas de memoria:
La memoria se divide en bloques de tamaño fijo llamados páginas (típicamente 4 KB en sistemas x86/x86_64). El sistema operativo gestiona la memoria en unidades de páginas, no bytes individuales. Cuando tu programa solicita memoria, el sistema operativo asigna páginas completas, aunque solo uses una porción de ellas.

Figure 1:Proceso de traducción de direcciones virtuales a físicas mediante la MMU (Memory Management Unit) y la tabla de páginas.
Segmentación de la Memoria¶
Un programa en ejecución divide su espacio de memoria en las siguientes áreas:
.text (Código) : Almacena el código ejecutable del programa, es decir, las instrucciones que ejecuta la CPU. Este segmento es de solo lectura para prevenir modificaciones accidentales o maliciosas del código durante la ejecución.
.rodata (Datos de solo lectura) : Contiene datos constantes y literales de cadena, como "Hola, mundo". Al igual que .text, este segmento es de solo lectura.
.data (Datos inicializados) : Almacena variables globales y estáticas que han sido explícitamente inicializadas en el código fuente.
.bss (Block Started by Symbol) : Contiene variables globales y estáticas (static). Que deben ser inicializadas, pero el sistema operativo
les dará un valore en cero al cargar el programa.
La palabra clave extern¶
La palabra clave extern se utiliza para declarar una variable global que está definida en otro archivo fuente. No crea una variable, sino que le dice al compilador: “Esta variable existe en otro lugar, confía en mí. El enlazador (linker) se encargará de encontrarla”.
Ejemplo:
archivo1.c
#include <stdio.h>
// Definición de la variable global
int contador_global = 42;
void imprimir_contador(); // Prototipo de la función en archivo2.c
int main() {
imprimir_contador();
return 0;
}archivo2.c
#include <stdio.h>
// Declaración de la variable externa
extern int contador_global;
void imprimir_contador() {
printf("El contador global es: %d\n", contador_global);
}Al compilar y enlazar ambos archivos (gcc archivo1.c archivo2.c -o programa), el enlazador resolverá la referencia a contador_global en archivo2.c con la definición en archivo1.c.
Si las variables globales tenian problemas, las variables globales compartidas
entre varios archivos son aún mas problemáticas, ver Regla 0x000Bh: No se permite el uso de variables globales.
Heap (Montón) : Zona de memoria destinada a la asignación dinámica. Crece desde direcciones bajas hacia direcciones altas. Su gestión es responsabilidad del programador.
Stack (Pila) : Zona de memoria para variables locales y gestión de llamadas a funciones. Crece desde direcciones altas hacia direcciones bajas. Su gestión es automática.
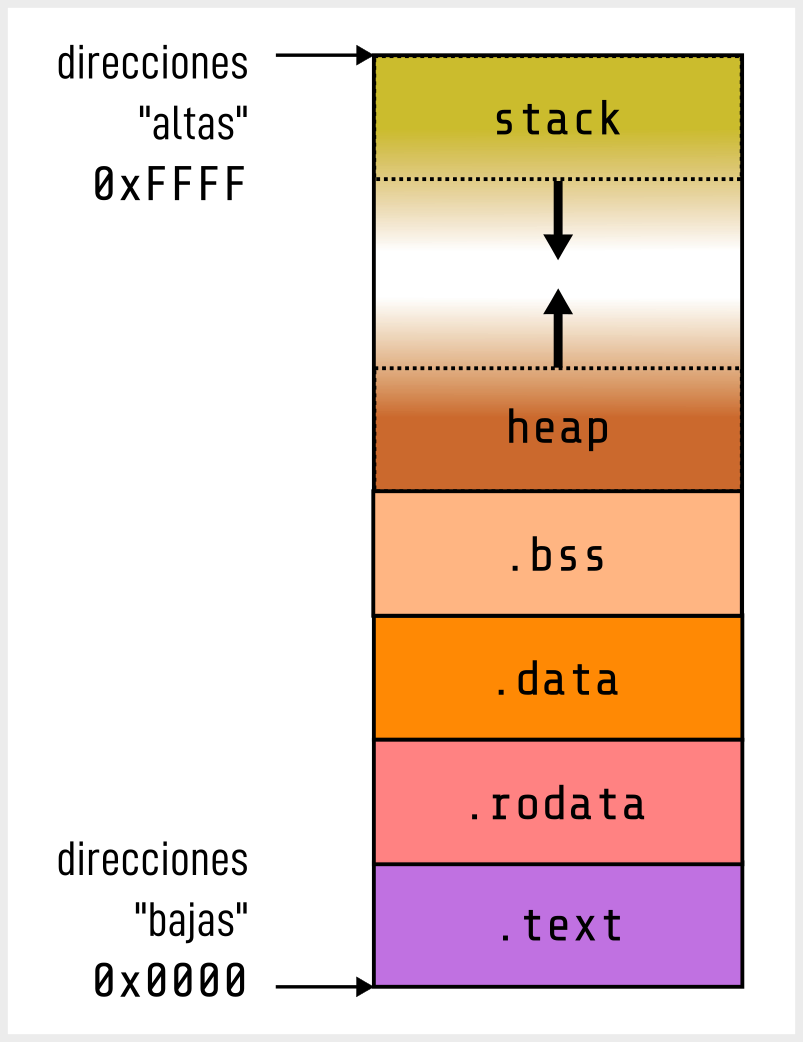
Figure 2:Organización típica de la memoria de un proceso en sistemas Unix/Linux.
La Pila (Stack)¶
La pila es una estructura de datos fundamental en la ejecución de programas. Su nombre proviene de la analogía con una pila de platos: el último elemento añadido es el primero en ser retirado.
Funcionamiento¶
La pila opera bajo el principio LIFO (Last-In, First-Out): el último elemento que entra es el primero en salir, similar a una pila de platos donde solo podés tomar el plato superior. Cada vez que llamás a una función, el sistema reserva un nuevo marco de pila (stack frame) que contiene las variables locales, los parámetros y la dirección de retorno. Cuando la función termina, ese marco se libera automáticamente.
Este mecanismo automático es extremadamente eficiente porque simplemente implica mover un puntero (el stack pointer) que indica la cima de la pila. Al entrar a una función, el puntero se mueve hacia abajo para hacer espacio; al salir, se mueve hacia arriba, “liberando” el espacio sin necesidad de limpiarlo explícitamente.
Ejemplo conceptual:
void funcion_b()
{
int z = 30;
// Stack: [x=10] [y=20] [z=30] <- cima
// Al retornar, z desaparece automáticamente
}
void funcion_a()
{
int y = 20;
// Stack: [x=10] [y=20] <- cima
funcion_b();
// Stack: [x=10] [y=20] <- cima (z ya no existe)
}
int main()
{
int x = 10;
// Stack: [x=10] <- cima
funcion_a();
// Stack: [x=10] <- cima (y ya no existe)
return 0;
}Anatomía de un Stack Frame¶
Cada llamada a función crea un stack frame (marco de pila) que contiene toda la información necesaria para ejecutar esa función y retornar correctamente. Comprender la estructura de un stack frame es fundamental para entender cómo funcionan las llamadas a funciones y por qué ciertos errores ocurren.
Estructura típica de un stack frame:

Figure 3:Estructura detallada de un stack frame mostrando la organización de parámetros, dirección de retorno, base pointer, variables locales y temporales.
Registros clave involucrados:
Stack Pointer (SP): Apunta siempre a la cima del stack. Se mueve con cada
pushypop.Base Pointer (BP o Frame Pointer): Apunta a la base del frame actual. Permite acceder a parámetros y variables locales con offsets fijos.
Secuencia de una llamada a función:
Preparación (caller):
Los argumentos se colocan en el stack (o registros, según la convención).
Se ejecuta la instrucción
CALL, que:Guarda la dirección de retorno en el stack
Salta a la dirección de la función
Prólogo (callee):
Se guarda el Base Pointer anterior
El Base Pointer actual se establece al Stack Pointer
Se reserva espacio para variables locales (se decrementa el SP)
Ejecución:
El cuerpo de la función se ejecuta
Las variables locales se acceden mediante offsets desde el BP
Epílogo (callee):
Se restaura el Stack Pointer al Base Pointer
Se restaura el Base Pointer anterior
Se ejecuta
RETURN, que:Extrae la dirección de retorno del stack
Salta a esa dirección
Limpieza (caller):
Se limpia el espacio usado para argumentos (según la convención)
Ejemplo en código assembly (x86-64 simplificado):
funcion:
push rbp ; Guardar frame pointer anterior
mov rbp, rsp ; Establecer nuevo frame pointer
sub rsp, 16 ; Reservar espacio para variables locales
; ... cuerpo de la función ...
mov rsp, rbp ; Restaurar stack pointer
pop rbp ; Restaurar frame pointer anterior
ret ; RetornarContenido del Stack¶
La pila almacena:
Variables locales de funciones.
Parámetros pasados a las funciones.
Direcciones de retorno que indican dónde debe continuar la ejecución después de que una función termine.
Información de estado del procesador (registros salvados).
Ventajas y Desventajas¶
Ventajas:
Acceso extremadamente rápido a las variables.
Gestión automática: no hay riesgo de fugas de memoria.
La localidad de referencia mejora el rendimiento del caché.
Desventajas:
Tamaño limitado y fijo (típicamente entre 1 MB y 8 MB en sistemas modernos).
No es posible cambiar el tamaño de las variables en tiempo de ejecución.
Las variables solo existen dentro de su ámbito léxico (scope).
Riesgo de stack overflow si se realizan llamadas recursivas profundas o se declaran arreglos muy grandes.
Ejemplo del error común:
int *funcion_incorrecta()
{
int valor = 42;
return &valor; // ERROR: retorna dirección de variable local
// 'valor' desaparece al salir de la función
}
int *funcion_correcta()
{
int *valor = malloc(sizeof(*valor));
if (valor == NULL)
{
return NULL;
}
*valor = 42;
return valor; // CORRECTO: la memoria persiste
// El llamador debe liberar esta memoria
}El Montón (Heap)¶
El heap es una región de memoria diseñada para la asignación dinámica. A diferencia de la pila, el heap permite solicitar memoria en tiempo de ejecución y mantenerla disponible hasta que explícitamente decidás liberarla.
Concepto¶
El heap puede visualizarse como una gran “reserva” de memoria disponible para el programa. Cuando necesitás un bloque de memoria de tamaño variable o que persista más allá del alcance de una función, recurrís al heap mediante funciones especializadas de asignación de memoria.
A diferencia del stack, donde el compilador y el sistema operativo gestionan automáticamente la creación y destrucción de variables, en el heap el programador tiene control total: decidís cuándo solicitar memoria y cuándo devolverla al sistema. Esta flexibilidad otorga un poder considerable, pero también impone una gran responsabilidad.
¿Cuándo usar el heap?
Usá el heap cuando:
No conocés el tamaño de los datos en tiempo de compilación.
Los datos deben persistir después de que la función que los creó retorne.
Necesitás grandes cantidades de memoria que excederían el tamaño limitado del stack.
Querés crear estructuras de datos complejas como listas enlazadas, árboles o grafos.
¿Cuándo usar el stack?
Usá el stack cuando:
El tamaño de los datos es conocido en tiempo de compilación y es pequeño.
Los datos solo son necesarios dentro del ámbito de la función actual.
Querés la máxima eficiencia de acceso a memoria.
Ventajas y Desventajas¶
Ventajas:
Flexibilidad total: podés solicitar la cantidad exacta de memoria que necesitás en tiempo de ejecución.
Persistencia: la memoria permanece válida hasta que la liberás explícitamente con
free.Tamaño mayor: el límite depende de la memoria disponible en el sistema, no de un tamaño de pila fijo.
Desventajas:
Acceso más lento que el stack debido a la indirección y la fragmentación.
Requiere gestión manual, lo que introduce riesgos de errores como fugas de memoria (memory leaks) y accesos inválidos.
Fragmentación de memoria a lo largo del tiempo.
Posibilidad de errores sutiles difíciles de detectar: accesos después de liberar memoria, dobles liberaciones, pérdida de referencias.
Comparación Stack vs Heap¶
La siguiente tabla resume las diferencias clave entre el stack y el heap para ayudarte a decidir cuál usar en cada situación:
Table 1:Comparación entre Stack y Heap
| Característica | Stack | Heap |
|---|---|---|
| Gestión | Automática | Manual |
| Tamaño | Limitado (1-8 MB típico) | Grande (limitado por RAM) |
| Tamaño en tiempo de compilación | Debe ser conocido | Puede ser dinámico |
| Persistencia | Solo dentro de la función | Hasta que se libere |
| Fragmentación | No ocurre | Puede ocurrir |
| Riesgo de errores | Bajo (overflow) | Alto (leaks, punteros colgantes) |
| Uso típico | Variables locales pequeñas | Estructuras grandes o dinámicas |
Regla práctica: Usá el stack siempre que puedas (por velocidad y simplicidad), y recurrí al heap solo cuando sea necesario (por flexibilidad).
El Allocator: Gestión Interna del Heap¶
Cuando llamás a malloc o calloc, no estás interactuando directamente con el sistema operativo en cada llamada. En cambio, estas funciones son parte de un subsistema llamado allocator (asignador de memoria) que gestiona el heap de tu proceso.
¿Cómo funciona el allocator?
El allocator mantiene su propia estructura de datos para rastrear qué bloques del heap están libres y cuáles están ocupados. Existen varias estrategias de implementación, pero todas deben resolver dos problemas fundamentales:
Al asignar: ¿Qué bloque libre usar cuando hay varios disponibles?
Al liberar: ¿Cómo marcar el bloque como libre y potencialmente fusionarlo con bloques adyacentes?
Estructura típica de un bloque de memoria:

Figure 4:Estructura de un bloque de memoria en el heap, mostrando el header con metadata, el área de datos del usuario, y el footer opcional.
El header típicamente contiene:
Tamaño del bloque (en bytes)
Flag de ocupado/libre (típicamente en el bit menos significativo del tamaño)
Punteros a bloques adyacentes (en implementaciones de lista enlazada)
Estrategias de asignación:
First Fit (Primer ajuste):
Busca desde el inicio del heap hasta encontrar el primer bloque libre suficientemente grande.
Ventaja: Rápido (termina apenas encuentra un bloque).
Desventaja: Tiende a fragmentar la parte inicial del heap.
Best Fit (Mejor ajuste):
Busca en todo el heap el bloque libre más pequeño que satisfaga la solicitud.
Ventaja: Minimiza el desperdicio de memoria.
Desventaja: Lento (debe recorrer toda la lista) y crea muchos bloques diminutos inutilizables.
Next Fit (Siguiente ajuste):
Como First Fit, pero continúa desde donde terminó la última búsqueda.
Ventaja: Distribuye mejor las asignaciones por todo el heap.
Desventaja: Aún puede fragmentar.
Segregated Free Lists (Listas libres segregadas):
Mantiene listas separadas para bloques de diferentes tamaños.
Ventaja: Muy eficiente para patrones de asignación predecibles.
Desventaja: Más complejo de implementar y mantener.
Interacción con el sistema operativo:
El allocator solicita memoria al sistema operativo en grandes cantidades (típicamente mediante sbrk() o mmap() en Unix/Linux) y luego la subdivide según las necesidades del programa. Esto reduce enormemente el número de llamadas al sistema, que son costosas.

Figure 5:Flujo de interacción entre el programa, las funciones de memoria (malloc/calloc/free), el allocator interno que mantiene un pool de memoria, y ocasionalmente el sistema operativo que proporciona acceso a la RAM física.
Coalescing (Fusión de bloques):
Cuando liberás un bloque con free(), el allocator intenta fusionarlo con bloques libres adyacentes para crear bloques más grandes. Esto ayuda a combatir la fragmentación externa.

Figure 6:Proceso de coalescing (fusión) donde bloques libres adyacentes (LIBRE-B y LIBRE-C) se combinan en un único bloque más grande (LIBRE-BC fusionado).
Herramienta Clave: Punteros¶
Los punteros son el mecanismo fundamental que permite trabajar con memoria dinámica en C. Un puntero no almacena un valor directo, sino la dirección de memoria donde se encuentra ese valor.
El Puntero void *: Puntero Genérico¶
Un void * es un puntero especial que puede apuntar a cualquier tipo de dato. No tiene asociado un tipo específico, por lo que:
No puede ser desreferenciado directamente.
No se puede hacer aritmética con él (no sabe el tamaño del tipo).
Puede convertirse implícitamente a cualquier otro tipo de puntero.
Uso principal:
Las funciones de memoria como malloc retornan void * porque no saben qué tipo de dato vas a almacenar:
void *memoria_generica = malloc(100); // void *, no sabemos qué tipo
int *enteros = memoria_generica; // Conversión implícita a int *
char *caracteres = memoria_generica; // O a char *, según necesitesLimitaciones:
void *ptr = malloc(10 * sizeof(int));
// ERROR: No se puede desreferenciar void *
// *ptr = 42;
// CORRECTO: Convertir primero
int *int_ptr = (int *)ptr;
*int_ptr = 42;
// ERROR: No se puede hacer aritmética con void *
// ptr = ptr + 1; // ¿Cuántos bytes avanzar?
// CORRECTO: Convertir a tipo concreto primero
int_ptr = int_ptr + 1; // Avanza sizeof(int) bytesCasteos Avanzados de Punteros¶
Los casteos de punteros en C son una herramienta poderosa pero peligrosa. Comprender los casteos avanzados, especialmente los punteros a arrays, es esencial para trabajar con memoria dinámica multidimensional y estructuras de datos complejas.
Casteos Básicos entre Tipos de Punteros¶
El casteo más simple convierte un puntero de un tipo a otro:
int *int_ptr = malloc(sizeof(int));
char *char_ptr = (char *)int_ptr; // Cast explícito
// Reinterpretar los bytes:
*int_ptr = 0x41424344;
printf("%c\n", char_ptr[0]); // Imprime 'D' (little-endian)Punteros a Punteros y Arrays Dinámicos 2D¶
Un patrón común es usar punteros a punteros para crear arrays bidimensionales dinámicos:
// Array 2D: 3 filas, 4 columnas
int **matriz = malloc(3 * sizeof(int *));
for (int i = 0; i < 3; i++)
{
matriz[i] = malloc(4 * sizeof(int));
}
// Acceso: matriz[fila][columna]
matriz[0][0] = 10;
matriz[2][3] = 99;
// Liberar: en orden inverso
for (int i = 0; i < 3; i++)
{
free(matriz[i]);
}
free(matriz);Visualización en memoria:

Figure 7:Estructura de int **matriz mostrando un array de punteros donde cada puntero apunta a una fila diferente. Las filas están dispersas en memoria (no contiguas), lo que resulta en mala localidad de caché.
Desventaja: Las filas no están contiguas en memoria, lo que reduce la localidad del caché.
Puntero a Array: (*)[N]¶
Un puntero a array es fundamentalmente diferente de un puntero a puntero. Apunta a un array completo como una unidad, no a un elemento individual.
Sintaxis:
int (*ptr)[4]; // Puntero a array de 4 enterosLos paréntesis son cruciales:
int (*ptr)[4]→ Puntero a array de 4 intsint *ptr[4]→ Array de 4 punteros a int (¡completamente diferente!)
Uso principal: Trabajar con arrays 2D contiguos en memoria.
Ejemplo fundamental:
// Declaración de array 2D tradicional
int matriz[3][4] = {
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 10, 11, 12}
};
// Puntero a array de 4 enteros
int (*ptr)[4] = matriz;
// Acceso equivalente:
printf("%d\n", matriz[1][2]); // 7
printf("%d\n", ptr[1][2]); // 7
printf("%d\n", (*(ptr + 1))[2]); // 7 - explícito¿Qué significa int (*ptr)[4]?
ptres un punteroCuando desreferenciás
*ptr, obtenés un array de 4 enterosptr + 1avanzasizeof(int[4])bytes (16 bytes si int = 4 bytes)
Aritmética de punteros a array:
int (*ptr)[4] = matriz;
// ptr apunta a matriz[0] (toda la primera fila)
// ptr + 1 apunta a matriz[1] (toda la segunda fila)
// ptr + 2 apunta a matriz[2] (toda la tercera fila)
// Cada incremento salta 4 * sizeof(int) bytesArrays 2D Contiguos con Punteros a Array¶
La verdadera potencia de (*)[N] aparece al trabajar con memoria dinámica contígua:
Problema: Querés un array 2D dinámico donde todos los elementos estén contiguos (mejor para el caché).
Solución:
#include <stdio.h>
#include <stdlib.h>
// Crear matriz 2D contígua: filas × columnas
int (*crear_matriz_contigua(size_t filas, size_t columnas))[columnas]
{
// Asignar toda la memoria de una vez
int (*matriz)[columnas] = malloc(filas * sizeof(*matriz));
if (matriz == NULL)
{
return NULL;
}
// Inicializar
for (size_t i = 0; i < filas; i++)
{
for (size_t j = 0; j < columnas; j++)
{
matriz[i][j] = 0;
}
}
return matriz;
}
int main()
{
size_t filas = 3;
size_t columnas = 4;
// Nota: necesitamos VLA (Variable Length Array) o C11
int (*matriz)[columnas] = crear_matriz_contigua(filas, columnas);
if (matriz == NULL)
{
return 1;
}
// Llenar la matriz
for (size_t i = 0; i < filas; i++)
{
for (size_t j = 0; j < columnas; j++)
{
matriz[i][j] = (int)(i * columnas + j);
}
}
// Acceso natural: matriz[i][j]
printf("matriz[1][2] = %d\n", matriz[1][2]);
// Liberar: una sola llamada
free(matriz);
return 0;
}Visualización en memoria:
![Comparación entre puntero a puntero (int **) con filas dispersas y puntero a array (int (*)[N]) con datos contiguos. La disposición contigua mejora significativamente la localidad de caché.](/build/pointer_to_array-41599716ad368a5a7c2c5cdd169f439b.svg)
Figure 8:Comparación entre puntero a puntero (int **) con filas dispersas y puntero a array (int (*)[N]) con datos contiguos. La disposición contigua mejora significativamente la localidad de caché.
Casteo a Puntero a Array¶
A veces necesitás reinterpretar memoria asignada como array multidimensional:
// Asignar memoria plana
int *memoria_plana = malloc(3 * 4 * sizeof(int));
// Reinterpretar como matriz 3×4
int (*matriz)[4] = (int (*)[4])memoria_plana;
// Ahora podés usar sintaxis de array 2D:
matriz[0][0] = 1;
matriz[1][2] = 7;
matriz[2][3] = 12;
// El acceso matriz[i][j] se traduce a:
// memoria_plana[i * 4 + j]Equivalencia:
// Estas tres formas son equivalentes:
matriz[i][j]
(*(matriz + i))[j]
memoria_plana[i * 4 + j]Ejemplo Completo: Múltiples Representaciones¶
#include <stdio.h>
#include <stdlib.h>
void imprimir_por_puntero_plano(int *arr, size_t filas, size_t cols)
{
printf("Como puntero plano:\n");
for (size_t i = 0; i < filas * cols; i++)
{
printf("%2d ", arr[i]);
if ((i + 1) % cols == 0) printf("\n");
}
}
void imprimir_por_puntero_a_array(int (*arr)[4], size_t filas)
{
printf("Como puntero a array:\n");
for (size_t i = 0; i < filas; i++)
{
for (size_t j = 0; j < 4; j++)
{
printf("%2d ", arr[i][j]);
}
printf("\n");
}
}
int main()
{
// Asignar memoria contígua para 3×4 enteros
int *memoria = malloc(3 * 4 * sizeof(int));
if (memoria == NULL)
{
return 1;
}
// Llenar con valores
for (int i = 0; i < 12; i++)
{
memoria[i] = i + 1;
}
// Representación 1: Puntero plano
imprimir_por_puntero_plano(memoria, 3, 4);
printf("\n");
// Representación 2: Casteo a puntero a array
int (*matriz)[4] = (int (*)[4])memoria;
imprimir_por_puntero_a_array(matriz, 3);
printf("\n");
// Acceso directo con ambas representaciones:
printf("memoria[5] = %d\n", memoria[5]); // 6
printf("matriz[1][1] = %d\n", matriz[1][1]); // 6 (mismo elemento)
// Modificar a través de matriz
matriz[2][3] = 99;
printf("memoria[11] = %d\n", memoria[11]); // 99 (cambio reflejado)
free(memoria);
return 0;
}Typedef para Simplificar¶
Los punteros a arrays pueden ser difíciles de leer. Los typedef ayudan:
// Sin typedef (difícil de leer):
int (*crear_matriz(size_t n))[10]
{
return malloc(n * sizeof(int[10]));
}
// Con typedef (más claro):
typedef int fila_t[10]; // fila_t es un array de 10 ints
fila_t *crear_matriz(size_t n)
{
return malloc(n * sizeof(fila_t));
}
// Uso:
fila_t *matriz = crear_matriz(5);
matriz[0][0] = 42; // Funciona igual
free(matriz);Otro ejemplo con struct:
typedef struct {
int datos[4];
} fila_estructurada_t;
// Más legible que int (*)[4]
fila_estructurada_t *matriz = malloc(3 * sizeof(*matriz));
matriz[0].datos[0] = 10;Limitaciones y Consideraciones¶
1. Compatibilidad con C99/C11:
El tamaño del array debe ser conocido en tiempo de compilación, o necesitás VLAs (Variable Length Arrays, C99):
// OK en C99+ con VLAs:
int (*crear(size_t cols))[cols]
{
return malloc(5 * sizeof(int[cols]));
}
// NO OK en C89:
// El compilador necesita conocer cols en compile-time2. Portabilidad:
VLAs en tipos de retorno no son universalmente soportados. Para máxima portabilidad:
// Usar typedef con tamaño fijo:
typedef int fila_fija_t[10];
fila_fija_t *crear(size_t filas)
{
return malloc(filas * sizeof(fila_fija_t));
}
// O usar void * y castear:
void *crear_generico(size_t filas, size_t cols)
{
return malloc(filas * cols * sizeof(int));
}3. Debugging:
Los punteros a arrays pueden ser confusos en debuggers. A veces es más claro usar puntero plano con acceso manual:
// Más fácil de debuggear:
int *arr = malloc(filas * cols * sizeof(int));
int elemento = arr[i * cols + j]; // Cálculo explícitoFunciones de Gestión de Memoria (<stdlib.h>)¶
Las funciones de gestión de memoria dinámica están declaradas en el archivo de
cabecera <stdlib.h>. Estas funciones permiten solicitar y liberar bloques de
memoria del heap durante la ejecución del programa.
malloc (Memory Allocation)¶
Sintaxis¶
void *malloc(size_t size);Propósito¶
Reserva un bloque contiguo de size bytes en el heap. La memoria reservada no está inicializada y contiene valores indeterminados (basura). Esto significa que los bytes asignados pueden contener cualquier valor que haya quedado de un uso previo de esa región de memoria.
La función retorna un puntero de tipo void *, que es un puntero genérico que puede convertirse implícitamente a cualquier tipo de puntero en C. Esto permite usar malloc para asignar memoria para cualquier tipo de dato.
Valor de Retorno¶
Un puntero de tipo
void *a la primera dirección del bloque reservado si la operación es exitosa.NULLsi no hay suficiente memoria disponible o sisizees 0 (comportamiento dependiente de la implementación).
¿Por qué la memoria no está inicializada?¶
Por razones de eficiencia. Inicializar la memoria tiene un costo computacional, y en muchos casos el programador va a sobrescribir inmediatamente esos valores con datos útiles. Si necesitás memoria inicializada a cero, usá calloc en su lugar.
Uso Correcto¶
Según la Regla 0x0019h: Siempre verificá la asignación exitosa de memoria dinámica, siempre debés verificar que la asignación de memoria fue exitosa. Además, la Regla 0x0026h: Usá siempre sizeof en las asignaciones de memoria dinámica establece que debés usar sizeof para calcular el tamaño necesario en lugar de valores literales, y preferir sizeof(*puntero) sobre sizeof(tipo) para evitar errores si el tipo cambia.
La Regla 0x001Bh: No mezcles operaciones de asignación y comparación en una sola línea indica que no debés mezclar operaciones de asignación y comparación en una sola línea.
#include <stdio.h>
#include <stdlib.h>
int main()
{
int *numeros = NULL;
size_t cantidad = 5;
// Asignación de memoria
numeros = malloc(cantidad * sizeof(*numeros));
// Verificación del resultado
if (numeros == NULL)
{
fprintf(stderr, "Error: No se pudo asignar memoria.\n");
return 1;
}
// Uso de la memoria
for (size_t i = 0; i < cantidad; i++)
{
numeros[i] = (int)i * 10;
}
// Liberación de la memoria
free(numeros);
numeros = NULL;
return 0;
}calloc (Contiguous Allocation)¶
Sintaxis¶
void *calloc(size_t num_elements, size_t element_size);Propósito¶
Reserva memoria para un arreglo de num_elements elementos, cada uno de tamaño element_size bytes. La diferencia fundamental con malloc es que calloc inicializa todos los bytes a cero.
El tamaño total reservado es num_elements * element_size bytes. La función realiza esta multiplicación internamente, lo que puede ser más seguro que calcularla manualmente con malloc, ya que algunas implementaciones de calloc verifican el desbordamiento (overflow) en esta multiplicación.
Ventajas¶
Inicialización automática: útil cuando necesitás garantizar que la memoria comienza en un estado conocido.
Claridad semántica: el nombre y los parámetros indican que estás creando un arreglo.
Seguridad: la separación de los parámetros hace explícita la intención y puede ayudar a prevenir errores de cálculo de tamaño.
¿Cuándo usar calloc vs malloc?¶
Usá calloc cuando:
Necesitás que la memoria esté inicializada a cero.
Estás creando un arreglo y querés que tu código sea más claro.
Trabajás con estructuras que contienen punteros que deben ser
NULLinicialmente.
Usá malloc cuando:
Vas a sobrescribir inmediatamente todos los valores.
Querés máxima eficiencia y no necesitás inicialización.
Estás asignando memoria para un único elemento (no un arreglo).
#include <stdio.h>
#include <stdlib.h>
int main()
{
size_t cantidad = 5;
int *arreglo = calloc(cantidad, sizeof(*arreglo));
if (arreglo == NULL)
{
fprintf(stderr, "Error: No se pudo asignar memoria.\n");
return 1;
}
// Todos los elementos están inicializados en 0
for (size_t i = 0; i < cantidad; i++)
{
printf("arreglo[%zu] = %d\n", i, arreglo[i]);
}
free(arreglo);
arreglo = NULL;
return 0;
}realloc (Re-allocation)¶
Sintaxis¶
void *realloc(void *ptr, size_t new_size);Propósito¶
Cambia el tamaño de un bloque de memoria previamente asignado.
ptr: Puntero al bloque de memoria original. Si esNULL,reallocse comporta comomalloc(new_size).new_size: Nuevo tamaño en bytes.
Comportamiento¶
Si
new_sizees mayor que el tamaño original:Intenta expandir el bloque actual si hay espacio contiguo.
Si no es posible, busca un nuevo bloque de memoria lo suficientemente grande, copia el contenido del bloque antiguo al nuevo, y libera el bloque antiguo.
La memoria adicional no se inicializa.
Si
new_sizees menor que el tamaño original:El bloque se trunca. Los datos al final se pierden.
Si
new_sizees 0:El comportamiento es dependiente de la implementación. Puede liberar la memoria (equivalente a
free(ptr)) o retornarNULL.
Valor de Retorno¶
Un puntero al bloque de memoria redimensionado (que puede ser la misma dirección o una nueva).
NULLsi la operación falla. En este caso, el bloque de memoria original no se libera y sigue siendo válido.
Uso Seguro¶
El error más común con realloc es perder la referencia al bloque original si la función falla por lo que es necesario un puntero temporal para manejar realloc de forma segura.
Incorrecto:
// ¡PELIGRO! Si realloc falla, se pierde el puntero original
ptr = realloc(ptr, nuevo_tamano);
if (ptr == NULL) {
// Fuga de memoria: el bloque original se perdió
}Correcto:
#include <stdlib.h>
int *numeros = malloc(5 * sizeof(*numeros));
// ...
size_t nuevo_tamano = 10;
int *temp = realloc(numeros, nuevo_tamano * sizeof(*temp));
if (temp == NULL) {
// realloc falló, pero 'numeros' sigue siendo válido
fprintf(stderr, "Error: No se pudo redimensionar la memoria.\n");
free(numeros); // Liberar el bloque original
return 1;
}
// Éxito: ahora 'numeros' puede apuntar al nuevo bloque
numeros = temp;free (Liberación)¶
Sintaxis¶
void free(void *ptr);Propósito¶
Libera un bloque de memoria previamente reservado, devolviéndolo al sistema operativo para que pueda ser reutilizado.
Reglas Fundamentales¶
Según la Regla 0x001Ah: Liberá siempre la memoria dinámica y prevení punteros colgantes, debés:
Liberar siempre la memoria dinámica que asignaste.
Asignar
NULLal puntero inmediatamente después de liberarlo para prevenir punteros colgantes.
Es seguro llamar a free(NULL), la función simplemente no hace nada.
free(ptr);
ptr = NULL; // Previene el uso accidental del puntero colganteErrores Comunes y Peligros¶
La gestión manual de memoria es una fuente frecuente de errores en C. Comprender estos errores y cómo prevenirlos es fundamental para escribir código robusto.
Memory Leak (Fuga de Memoria)¶
Una fuga de memoria ocurre cuando se pierde la referencia a un bloque de memoria reservado sin haberlo liberado con free. La memoria queda inutilizable para el programa hasta que este termina.
Ejemplo Problemático¶
#include <stdlib.h>
void funcion_con_fuga()
{
int *datos = malloc(100 * sizeof(*datos));
// Se realizan operaciones...
// ERROR: La función termina sin liberar 'datos'
// El bloque de memoria se pierde
}Solución¶
Asegurate de que cada asignación tenga su correspondiente liberación, siguiendo la Regla 0x001Ah: Liberá siempre la memoria dinámica y prevení punteros colgantes.
void funcion_sin_fuga()
{
int *datos = malloc(100 * sizeof(*datos));
if (datos == NULL)
{
return;
}
// Operaciones...
free(datos);
datos = NULL;
}Dangling Pointer (Puntero Colgante)¶
Un puntero colgante es un puntero que apunta a una dirección de memoria que ya ha sido liberada con free. Intentar acceder a través de él produce comportamiento indefinido.
Ejemplo Problemático¶
#include <stdlib.h>
#include <stdio.h>
int main()
{
int *ptr = malloc(sizeof(*ptr));
*ptr = 42;
free(ptr);
// ERROR: 'ptr' aún contiene la dirección liberada
printf("%d\n", *ptr); // Comportamiento indefinido
return 0;
}Solución¶
Asigná NULL al puntero inmediatamente después de llamar a free, como exige la Regla 0x001Ah: Liberá siempre la memoria dinámica y prevení punteros colgantes.
int main()
{
int *ptr = malloc(sizeof(*ptr));
*ptr = 42;
free(ptr);
ptr = NULL; // Previene el uso del puntero colgante
// Intentar desreferenciar ptr ahora causará un error inmediato
// en lugar de comportamiento indefinido silencioso
return 0;
}Double Free (Doble Liberación)¶
Intentar liberar el mismo bloque de memoria dos veces causa comportamiento indefinido y puede corromper la gestión de memoria del heap.
Ejemplo Problemático¶
#include <stdlib.h>
int main()
{
int *ptr = malloc(sizeof(*ptr));
free(ptr);
free(ptr); // ERROR: Doble liberación
return 0;
}Solución¶
Asignar NULL después de cada free previene este problema, ya que free(NULL) es una operación segura que no hace nada.
int main()
{
int *ptr = malloc(sizeof(*ptr));
free(ptr);
ptr = NULL;
free(ptr); // Seguro: free(NULL) no hace nada
return 0;
}Acceso Fuera de Límites¶
Leer o escribir fuera de los límites del bloque de memoria reservado corrompe datos adyacentes y causa comportamiento impredecible.
Ejemplo Problemático¶
#include <stdlib.h>
int main()
{
int *arreglo = malloc(5 * sizeof(*arreglo));
if (arreglo == NULL)
{
return 1;
}
// ERROR: Acceso fuera de límites
for (size_t i = 0; i <= 5; i++) // Debería ser i < 5
{
arreglo[i] = (int)i;
}
free(arreglo);
arreglo = NULL;
return 0;
}Solución¶
La Regla 0x0027h: Verificá siempre los límites de los arreglos antes de acceder a sus elementos exige verificar siempre los límites de los arreglos antes de acceder a sus elementos. La Regla 0x002Eh: Las variables que representan tamaños o índices de arreglos deben ser de tipo size_t establece que las variables que representan tamaños o índices de arreglos deben ser de tipo size_t.
int main()
{
size_t tamano = 5;
int *arreglo = malloc(tamano * sizeof(*arreglo));
if (arreglo == NULL)
{
return 1;
}
// Correcto: i < tamano previene el acceso fuera de límites
for (size_t i = 0; i < tamano; i++)
{
arreglo[i] = (int)i;
}
free(arreglo);
arreglo = NULL;
return 0;
}Uso de Memoria Después de free¶
Acceder a memoria después de liberarla es un error similar al puntero colgante.
Ejemplo Problemático¶
#include <stdlib.h>
#include <stdio.h>
int main()
{
int *ptr = malloc(sizeof(*ptr));
*ptr = 100;
free(ptr);
// ERROR: Uso de memoria liberada
printf("%d\n", *ptr);
return 0;
}Solución¶
Asegurate de no usar el puntero después de liberarlo, y asigná NULL para detectar errores fácilmente.
Seguridad de Memoria: Una Perspectiva Profunda¶
La seguridad de memoria (memory safety) es uno de los desafíos más importantes en programación de sistemas. Comprender por qué los errores de memoria son tan peligrosos requiere entender qué significa “comportamiento indefinido” y cómo puede ser explotado.
Comportamiento Indefinido (Undefined Behavior)¶
Cuando el estándar de C dice que una operación tiene “comportamiento indefinido” (UB), significa que absolutamente cualquier cosa puede pasar. El compilador no está obligado a hacer nada razonable.
¿Por qué existe el UB?
El comportamiento indefinido existe por dos razones principales:
Rendimiento: Verificar todos los accesos a memoria en tiempo de ejecución sería prohibitivamente lento. C delega la responsabilidad al programador para mantener la máxima velocidad.
Flexibilidad del compilador: El compilador puede hacer optimizaciones agresivas asumiendo que tu código no tiene UB. Si tenés UB, esas optimizaciones pueden hacer que tu programa haga cosas completamente inesperadas.
Ejemplos de UB en gestión de memoria:
// UB #1: Desreferenciar puntero NULL
int *ptr = NULL;
*ptr = 42; // Crash probable, pero no garantizado
// UB #2: Uso después de free
int *ptr = malloc(sizeof(int));
free(ptr);
*ptr = 42; // Puede parecer funcionar, pero es UB
// UB #3: Doble free
free(ptr);
free(ptr); // Puede corromper el heap
// UB #4: Acceso fuera de límites
int arr[10];
arr[15] = 42; // Puede sobrescribir otras variables
// UB #5: Retornar dirección de variable local
int *funcion() {
int x = 42;
return &x; // x desaparece al retornar
}Consecuencias del UB:
El comportamiento indefinido no solo causa crashes. Puede:
Parecer funcionar: El programa parece correr bien en tu máquina, pero falla en producción.
Funcionar hasta que cambies algo no relacionado: Agregar una línea de código en otro lado hace que el programa crashee, porque cambió el layout de memoria.
Ser explotado por atacantes: Los buffer overflows son la base de muchas vulnerabilidades de seguridad.
Ser “optimizado” por el compilador de forma sorprendente:
// El programador escribe: if (ptr != NULL) { *ptr = 42; } // Pero si el compilador ve *ptr antes del if, // puede asumir que ptr nunca es NULL (porque desreferenciarlo // cuando es NULL sería UB), y eliminar la verificación.
Vulnerabilidades Comunes¶
Los errores de memoria no son solo bugs: son vulnerabilidades de seguridad. Comprender los ataques comunes te ayuda a escribir código más defensivo.
Buffer Overflow:
Un buffer overflow ocurre cuando escribís más datos de los que un buffer puede contener, sobrescribiendo memoria adyacente.
void vulnerable()
{
char buffer[10];
char *datos_importantes = "SECRETO";
// Un atacante puede escribir más de 10 bytes:
strcpy(buffer, datos_maliciosos_largos);
// Ahora datos_importantes puede haber sido sobrescrito
}En el stack, un atacante puede sobrescribir la dirección de retorno para ejecutar código arbitrario:

Figure 9:Visualización de buffer overflow en el stack: antes del overflow el buffer tiene su espacio asignado y la dirección de retorno está protegida; después del overflow, datos excesivos (representados como ‘A’) sobrescriben el buffer, los datos intermedios, y finalmente corrompen la dirección de retorno, permitiendo potencialmente la ejecución de código malicioso.
Use-After-Free (UAF):
Usar memoria después de liberarla puede permitir que un atacante controle datos críticos:
struct usuario {
char nombre[50];
int es_admin;
};
struct usuario *usr = malloc(sizeof(*usr));
usr->es_admin = 0; // Usuario normal
free(usr);
// ... código intermedio ...
// Otro código asigna memoria que reutiliza el mismo espacio:
char *buffer = malloc(100);
strcpy(buffer, datos_del_atacante);
// Ahora usr apunta a memoria controlada por el atacante:
if (usr->es_admin) { // ⚠️ UAF: usa memoria liberada
// El atacante pudo sobrescribir es_admin a 1
dar_privilegios_admin();
}Double Free:
Liberar memoria dos veces puede corromper las estructuras internas del allocator, permitiendo ataques sofisticados:
free(ptr);
// ... código ...
free(ptr); // Corrompe la lista de bloques libres
// Asignaciones posteriores pueden retornar direcciones sobrepuestas:
int *a = malloc(100);
int *b = malloc(100);
// Ahora 'a' y 'b' podrían apuntar a la misma memoria!Estrategias Defensivas¶
1. Principio de mínimo privilegio: No uses más memoria de la que necesitás, y no la mantengas asignada más tiempo del necesario.
2. Verificación exhaustiva:
// No solo verificar malloc:
if (ptr == NULL) { /* error */ }
// También verificar límites:
if (indice >= tamano) { /* error */ }
// Y validar punteros recibidos:
if (ptr_entrada == NULL) { /* error */ }3. Inicialización defensiva:
// Inicializar punteros:
int *ptr = NULL;
// Después de free, anular:
free(ptr);
ptr = NULL;
// Inicializar estructuras completamente:
struct datos d = {0}; // Todos los campos en cero4. Encapsulación: Ocultá la gestión de memoria detrás de funciones:
// En lugar de exponer punteros directamente:
recurso_t *crear_recurso(void);
void usar_recurso(recurso_t *r);
void destruir_recurso(recurso_t *r);
// Los usuarios nunca ven malloc/free directamente5. Usar funciones seguras:
// En lugar de:
strcpy(dest, src); // No verifica límites
// Usar:
strncpy(dest, src, sizeof(dest) - 1);
dest[sizeof(dest) - 1] = '\0';
// O mejor aún, alocar dinámicamente con el tamaño correctoResumen de Buenas Prácticas¶
La gestión segura de memoria dinámica requiere disciplina y adherencia a un conjunto de prácticas probadas. Este resumen consolida las reglas fundamentales.
Inicializar Punteros¶
Siempre inicializá los punteros a NULL al declararlos si no tenés una dirección válida para asignarles inmediatamente. Esto está codificado en la Regla 0x0003h: Siempre debés inicializar las variables a un valor conocido y la Regla 0x0022h: Los punteros nulos deben ser inicializados y comparados con NULL, no con 0.
int *ptr = NULL;Verificar Asignaciones¶
Siempre comprobá si el valor devuelto por malloc o calloc es NULL antes de usar el puntero. La Regla 0x0019h: Siempre verificá la asignación exitosa de memoria dinámica lo exige explícitamente.
ptr = malloc(tamano);
if (ptr == NULL)
{
// Manejo de error
fprintf(stderr, "Error: No se pudo asignar memoria.\n");
return ERROR_MEMORIA;
}Liberar Memoria¶
Por cada asignación exitosa con malloc o calloc, debe haber una llamada correspondiente a free. La Regla 0x001Ah: Liberá siempre la memoria dinámica y prevení punteros colgantes establece esta simetría como obligatoria.
free(ptr);Anular Punteros Después de Liberar¶
Después de llamar a free(puntero), asigná puntero = NULL para evitar punteros colgantes. La Regla 0x001Ah: Liberá siempre la memoria dinámica y prevení punteros colgantes lo exige.
free(ptr);
ptr = NULL;Mantener Simetría¶
Intentá que la función que reserva la memoria sea también responsable de liberarla, o que haya una correspondencia clara, como crear_estructura() y destruir_estructura(). Esta práctica está documentada en la Regla 0x001Ah: Liberá siempre la memoria dinámica y prevení punteros colgantes.
recurso_t *crear_recurso()
{
recurso_t *r = malloc(sizeof(*r));
if (r == NULL)
{
return NULL;
}
// Inicialización...
return r;
}
void destruir_recurso(recurso_t *r)
{
if (r != NULL)
{
// Liberación de recursos internos...
free(r);
}
}Documentar Propiedad¶
La Regla 0x020Fh: Documentá la propiedad de los recursos al utilizar punteros exige que documentes claramente quién es el responsable de liberar la memoria cuando una función recibe o devuelve un puntero a memoria dinámica.
/**
* Crea un nuevo nodo de lista.
* @param valor El valor a almacenar en el nodo.
* @returns Un puntero al nuevo nodo. El llamador es responsable
* de liberar esta memoria con destruir_nodo().
* Retorna NULL si no hay memoria disponible.
*/
nodo_t *crear_nodo(int valor);Usar const Apropiadamente¶
Según la Regla 0x0021h: Los argumentos de tipo puntero deben ser const siempre que la función no los modifique, los argumentos de tipo puntero deben ser const siempre que la función no los modifique. Esto establece un contrato claro y permite al compilador detectar modificaciones no intencionales.
void imprimir_arreglo(const int *arreglo, size_t tamano)
{
for (size_t i = 0; i < tamano; i++)
{
printf("%d ", arreglo[i]);
}
printf("\n");
}Usar sizeof Correctamente¶
La Regla 0x0026h: Usá siempre sizeof en las asignaciones de memoria dinámica establece que debés usar siempre sizeof en las asignaciones de memoria dinámica, y preferir sizeof(*puntero) sobre sizeof(tipo).
// Preferido
int *ptr = malloc(n * sizeof(*ptr));
// Evitar
int *ptr = malloc(n * sizeof(int)); // Si el tipo de ptr cambia, esto fallaUsar size_t para Tamaños e Índices¶
La Regla 0x002Eh: Las variables que representan tamaños o índices de arreglos deben ser de tipo size_t exige que las variables que representan tamaños o índices de arreglos sean de tipo size_t.
size_t tamano = 10;
int *arreglo = malloc(tamano * sizeof(*arreglo));
for (size_t i = 0; i < tamano; i++)
{
arreglo[i] = 0;
}Verificar Límites¶
La Regla 0x0027h: Verificá siempre los límites de los arreglos antes de acceder a sus elementos exige verificar siempre los límites de los arreglos antes de acceder a sus elementos.
void establecer_elemento(int *arreglo, size_t tamano, size_t indice, int valor)
{
if (indice < tamano)
{
arreglo[indice] = valor;
}
}
(memoria-ejemplo-integrador)=
## Ejemplo Integrador: Arreglo Dinámico de Tamaño Fijo
Este ejemplo demuestra cómo aplicar las buenas prácticas de gestión de memoria en un caso realista: una estructura que encapsula un arreglo dinámico de enteros de tamaño fijo.
```c
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#define ERROR_MEMORIA -1
#define ERROR_INDICE -2
#define EXITO 0
typedef struct
{
int *datos;
size_t tamano;
} arreglo_t;
/**
* Crea un nuevo arreglo dinámico de tamaño fijo.
* @param tamano El tamaño del arreglo (debe ser mayor que 0).
* @returns Un puntero al arreglo creado. El llamador es responsable
* de liberar esta memoria con destruir_arreglo().
* Retorna NULL si no hay memoria disponible o si tamano es 0.
* @post El arreglo está inicializado con todos sus elementos en 0.
*/
arreglo_t *crear_arreglo(size_t tamano)
{
if (tamano == 0)
{
return NULL;
}
arreglo_t *arreglo = malloc(sizeof(*arreglo));
if (arreglo == NULL)
{
return NULL;
}
arreglo->datos = calloc(tamano, sizeof(*(arreglo->datos)));
if (arreglo->datos == NULL)
{
free(arreglo);
return NULL;
}
arreglo->tamano = tamano;
return arreglo;
}
/**
* Establece el valor de un elemento en el arreglo.
* @param arreglo Puntero al arreglo (no debe ser NULL).
* @param indice Índice del elemento a modificar.
* @param valor Nuevo valor para el elemento.
* @pre arreglo no debe ser NULL.
* @pre indice debe ser menor que el tamaño del arreglo.
* @returns EXITO si el valor se estableció correctamente,
* ERROR_INDICE si el índice es inválido.
*/
int establecer_elemento(arreglo_t *arreglo, size_t indice, int valor)
{
if (arreglo == NULL)
{
return ERROR_MEMORIA;
}
if (indice >= arreglo->tamano)
{
return ERROR_INDICE;
}
arreglo->datos[indice] = valor;
return EXITO;
}
/**
* Obtiene el valor de un elemento del arreglo.
* @param arreglo Puntero al arreglo (no debe ser NULL).
* @param indice Índice del elemento a obtener.
* @param valor_out Puntero donde se almacenará el valor (no debe ser NULL).
* @pre arreglo y valor_out no deben ser NULL.
* @pre indice debe ser menor que el tamaño del arreglo.
* @returns true si se obtuvo el elemento, false si algún parámetro es inválido.
*/
bool obtener_elemento(const arreglo_t *arreglo, size_t indice, int *valor_out)
{
if (arreglo == NULL || valor_out == NULL)
{
return false;
}
if (indice >= arreglo->tamano)
{
return false;
}
*valor_out = arreglo->datos[indice];
return true;
}
/**
* Calcula la suma de todos los elementos del arreglo.
* @param arreglo Puntero al arreglo (no debe ser NULL).
* @pre arreglo no debe ser NULL.
* @returns La suma de todos los elementos, o 0 si el arreglo es NULL.
*/
int sumar_elementos(const arreglo_t *arreglo)
{
if (arreglo == NULL)
{
return 0;
}
int suma = 0;
for (size_t i = 0; i < arreglo->tamano; i++)
{
suma = suma + arreglo->datos[i];
}
return suma;
}
/**
* Imprime todos los elementos del arreglo.
* @param arreglo Puntero al arreglo (no debe ser NULL).
* @pre arreglo no debe ser NULL.
*/
void imprimir_arreglo(const arreglo_t *arreglo)
{
if (arreglo == NULL)
{
return;
}
printf("Arreglo [tamaño: %zu]: [", arreglo->tamano);
for (size_t i = 0; i < arreglo->tamano; i++)
{
printf("%d", arreglo->datos[i]);
if (i < arreglo->tamano - 1)
{
printf(", ");
}
}
printf("]\n");
}
/**
* Destruye un arreglo y libera toda la memoria asociada.
* @param arreglo Puntero al arreglo a destruir. Puede ser NULL.
* @post Toda la memoria del arreglo es liberada.
*/
void destruir_arreglo(arreglo_t *arreglo)
{
if (arreglo != NULL)
{
if (arreglo->datos != NULL)
{
free(arreglo->datos);
}
free(arreglo);
}
}
int main()
{
size_t tamano = 8;
arreglo_t *mi_arreglo = crear_arreglo(tamano);
if (mi_arreglo == NULL)
{
fprintf(stderr, "Error: No se pudo crear el arreglo.\n");
return 1;
}
// Establecer algunos valores
for (size_t i = 0; i < tamano; i++)
{
if (establecer_elemento(mi_arreglo, i, (int)(i * i)) != EXITO)
{
fprintf(stderr, "Error: No se pudo establecer elemento.\n");
destruir_arreglo(mi_arreglo);
return 1;
}
}
imprimir_arreglo(mi_arreglo);
// Obtener y mostrar un elemento específico
int valor = 0;
if (obtener_elemento(mi_arreglo, 3, &valor))
{
printf("Elemento en índice 3: %d\n", valor);
}
// Calcular la suma
int suma = sumar_elementos(mi_arreglo);
printf("Suma de todos los elementos: %d\n", suma);
// Liberar recursos
destruir_arreglo(mi_arreglo);
return 0;
}Ejercicios¶
Solution to Exercise 1
#include <stdio.h>
#include <stdlib.h>
#define ERROR_MEMORIA 1
#define ERROR_ENTRADA 2
int main()
{
int *numeros = NULL;
size_t cantidad = 0;
int suma = 0;
printf("¿Cuántos números deseas ingresar? ");
if (scanf("%zu", &cantidad) != 1 || cantidad == 0)
{
fprintf(stderr, "Error: Entrada inválida.\n");
return ERROR_ENTRADA;
}
// Asignar memoria
numeros = malloc(cantidad * sizeof(*numeros));
if (numeros == NULL)
{
fprintf(stderr, "Error: No se pudo asignar memoria.\n");
return ERROR_MEMORIA;
}
// Leer números
printf("Ingresa %zu números:\n", cantidad);
for (size_t i = 0; i < cantidad; i++)
{
printf("Número %zu: ", i + 1);
if (scanf("%d", &numeros[i]) != 1)
{
fprintf(stderr, "Error: Entrada inválida.\n");
free(numeros);
numeros = NULL;
return ERROR_ENTRADA;
}
suma = suma + numeros[i];
}
// Calcular promedio
double promedio = (double)suma / (double)cantidad;
printf("El promedio es: %.2f\n", promedio);
// Liberar memoria
free(numeros);
numeros = NULL;
return 0;
}
```{exercise} Cadena Dinámica
:label: ej-memoria-cadena
Implementá una función `duplicar_cadena` que reciba una cadena de caracteres y devuelva una copia exacta de ella en memoria dinámica. La función debe tener la siguiente firma:
```c
char *duplicar_cadena(const char *original);La función debe:
Calcular el tamaño necesario (incluyendo el terminador nulo
\0).Reservar memoria dinámica para la copia.
Copiar el contenido caracter por caracter.
Retornar un puntero a la nueva cadena, o
NULLsi hay un error.
Luego, escribí un programa principal que use esta función para duplicar una cadena ingresada por el usuario.
```{solution} ej-memoria-cadena
:class: dropdown
```c
#include <stdio.h>
#include <stdlib.h>
/**
* Duplica una cadena en memoria dinámica.
* @param original Cadena a duplicar (no debe ser NULL).
* @returns Un puntero a la nueva cadena. El llamador es responsable
* de liberar esta memoria con free().
* Retorna NULL si original es NULL o no hay memoria disponible.
*/
char *duplicar_cadena(const char *original)
{
if (original == NULL)
{
return NULL;
}
// Calcular longitud de la cadena
size_t longitud = 0;
while (original[longitud] != '\0')
{
longitud = longitud + 1;
}
// Reservar memoria (longitud + 1 para el '\0')
char *copia = malloc((longitud + 1) * sizeof(*copia));
if (copia == NULL)
{
return NULL;
}
// Copiar caracter por caracter
for (size_t i = 0; i <= longitud; i++)
{
copia[i] = original[i];
}
return copia;
}
int main()
{
char original[100] = {0};
printf("Ingresa una cadena (máximo 99 caracteres): ");
if (fgets(original, sizeof(original), stdin) == NULL)
{
fprintf(stderr, "Error: No se pudo leer la cadena.\n");
return 1;
}
// Remover el salto de línea si existe
size_t longitud = 0;
while (original[longitud] != '\0' && original[longitud] != '\n')
{
longitud = longitud + 1;
}
original[longitud] = '\0';
char *copia = duplicar_cadena(original);
if (copia == NULL)
{
fprintf(stderr, "Error: No se pudo duplicar la cadena.\n");
return 1;
}
printf("Original: \"%s\"\n", original);
printf("Copia: \"%s\"\n", copia);
free(copia);
copia = NULL;
return 0;
}
```{exercise} Búsqueda en Arreglo Dinámico
:label: ej-memoria-busqueda
Implementá las siguientes funciones para trabajar con un arreglo dinámico de enteros:
```c
int *crear_arreglo_inicializado(size_t tamano, int valor_inicial);
int buscar_elemento(const int *arreglo, size_t tamano, int valor);
int contar_ocurrencias(const int *arreglo, size_t tamano, int valor);crear_arreglo_inicializado: Crea un arreglo dinámico donde todos los elementos tienen el valorvalor_inicial.buscar_elemento: Retorna el índice de la primera ocurrencia devaloren el arreglo, o -1 si no se encuentra.contar_ocurrencias: Retorna cuántas veces aparecevaloren el arreglo.
Escribí un programa principal que use estas funciones para crear un arreglo, inicializarlo, modificar algunos elementos, y luego buscar y contar ocurrencias de valores específicos.
```{solution} ej-memoria-busqueda
:class: dropdown
```c
#include <stdio.h>
#include <stdlib.h>
/**
* Crea un arreglo dinámico inicializado con un valor específico.
* @param tamano Tamaño del arreglo (debe ser mayor que 0).
* @param valor_inicial Valor con el que se inicializará cada elemento.
* @returns Un puntero al arreglo creado. El llamador es responsable
* de liberar esta memoria con free().
* Retorna NULL si tamano es 0 o no hay memoria disponible.
*/
int *crear_arreglo_inicializado(size_t tamano, int valor_inicial)
{
if (tamano == 0)
{
return NULL;
}
int *arreglo = malloc(tamano * sizeof(*arreglo));
if (arreglo == NULL)
{
return NULL;
}
for (size_t i = 0; i < tamano; i++)
{
arreglo[i] = valor_inicial;
}
return arreglo;
}
/**
* Busca la primera ocurrencia de un valor en el arreglo.
* @param arreglo Puntero al arreglo (no debe ser NULL).
* @param tamano Tamaño del arreglo.
* @param valor Valor a buscar.
* @returns El índice de la primera ocurrencia, o -1 si no se encuentra.
*/
int buscar_elemento(const int *arreglo, size_t tamano, int valor)
{
if (arreglo == NULL)
{
return -1;
}
for (size_t i = 0; i < tamano; i++)
{
if (arreglo[i] == valor)
{
return (int)i;
}
}
return -1;
}
/**
* Cuenta cuántas veces aparece un valor en el arreglo.
* @param arreglo Puntero al arreglo (no debe ser NULL).
* @param tamano Tamaño del arreglo.
* @param valor Valor a contar.
* @returns El número de ocurrencias del valor.
*/
int contar_ocurrencias(const int *arreglo, size_t tamano, int valor)
{
if (arreglo == NULL)
{
return 0;
}
int contador = 0;
for (size_t i = 0; i < tamano; i++)
{
if (arreglo[i] == valor)
{
contador = contador + 1;
}
}
return contador;
}
int main()
{
size_t tamano = 10;
int valor_inicial = 5;
int *arreglo = crear_arreglo_inicializado(tamano, valor_inicial);
if (arreglo == NULL)
{
fprintf(stderr, "Error: No se pudo crear el arreglo.\n");
return 1;
}
printf("Arreglo inicial (todos %d): ", valor_inicial);
for (size_t i = 0; i < tamano; i++)
{
printf("%d ", arreglo[i]);
}
printf("\n");
// Modificar algunos elementos
arreglo[2] = 10;
arreglo[5] = 10;
arreglo[7] = 15;
printf("Arreglo modificado: ");
for (size_t i = 0; i < tamano; i++)
{
printf("%d ", arreglo[i]);
}
printf("\n");
// Buscar valores
int buscar = 10;
int indice = buscar_elemento(arreglo, tamano, buscar);
if (indice != -1)
{
printf("Primera ocurrencia de %d: índice %d\n", buscar, indice);
}
else
{
printf("No se encontró %d en el arreglo\n", buscar);
}
// Contar ocurrencias
int ocurrencias = contar_ocurrencias(arreglo, tamano, buscar);
printf("El valor %d aparece %d veces\n", buscar, ocurrencias);
ocurrencias = contar_ocurrencias(arreglo, tamano, valor_inicial);
printf("El valor %d aparece %d veces\n", valor_inicial, ocurrencias);
free(arreglo);
arreglo = NULL;
return 0;
}
```{exercise} Matriz Dinámica
:label: ej-memoria-matriz
Implementá funciones para crear y manipular una matriz dinámica de enteros de tamaño $m \times n$:
```c
int **crear_matriz(size_t filas, size_t columnas);
void liberar_matriz(int **matriz, size_t filas);
void imprimir_matriz(int **matriz, size_t filas, size_t columnas);Asegurate de:
Liberar la memoria en el orden correcto (Regla
0x002Ah: Liberá la memoria en el orden inverso a su asignación).Verificar todas las asignaciones.
Manejar errores apropiadamente.
```{solution} ej-memoria-matriz
:class: dropdown
```c
#include <stdio.h>
#include <stdlib.h>
/**
* Crea una matriz dinámica de enteros.
* @param filas Número de filas.
* @param columnas Número de columnas.
* @returns Un puntero a la matriz creada. El llamador es responsable
* de liberar esta memoria con liberar_matriz().
* Retorna NULL si no hay memoria disponible.
*/
int **crear_matriz(size_t filas, size_t columnas)
{
int **matriz = malloc(filas * sizeof(*matriz));
if (matriz == NULL)
{
return NULL;
}
for (size_t i = 0; i < filas; i++)
{
matriz[i] = malloc(columnas * sizeof(*(matriz[i])));
if (matriz[i] == NULL)
{
// Liberar las filas ya asignadas
for (size_t j = 0; j < i; j++)
{
free(matriz[j]);
}
free(matriz);
return NULL;
}
// Inicializar la fila en 0
for (size_t j = 0; j < columnas; j++)
{
matriz[i][j] = 0;
}
}
return matriz;
}
/**
* Libera una matriz dinámica.
* @param matriz Puntero a la matriz. Puede ser NULL.
* @param filas Número de filas de la matriz.
*/
void liberar_matriz(int **matriz, size_t filas)
{
if (matriz == NULL)
{
return;
}
// Liberar en orden inverso: primero las filas, luego el arreglo
for (size_t i = 0; i < filas; i++)
{
free(matriz[i]);
}
free(matriz);
}
/**
* Imprime una matriz.
* @param matriz Puntero a la matriz (no debe ser NULL).
* @param filas Número de filas.
* @param columnas Número de columnas.
* @pre matriz no debe ser NULL.
*/
void imprimir_matriz(int **matriz, size_t filas, size_t columnas)
{
if (matriz == NULL)
{
return;
}
for (size_t i = 0; i < filas; i++)
{
for (size_t j = 0; j < columnas; j++)
{
printf("%4d ", matriz[i][j]);
}
printf("\n");
}
}
int main()
{
size_t filas = 3;
size_t columnas = 4;
int **matriz = crear_matriz(filas, columnas);
if (matriz == NULL)
{
fprintf(stderr, "Error: No se pudo crear la matriz.\n");
return 1;
}
// Llenar la matriz con valores
for (size_t i = 0; i < filas; i++)
{
for (size_t j = 0; j < columnas; j++)
{
matriz[i][j] = (int)(i * columnas + j);
}
}
printf("Matriz %zu x %zu:\n", filas, columnas);
imprimir_matriz(matriz, filas, columnas);
liberar_matriz(matriz, filas);
return 0;
}
```{exercise} Estructura con Memoria Dinámica
:label: ej-memoria-estructura
Implementá un tipo de dato `persona_t` que almacene información de una persona:
```c
typedef struct
{
char *nombre;
char *apellido;
int edad;
} persona_t;Implementá las siguientes funciones:
persona_t *crear_persona(const char *nombre, const char *apellido, int edad);
void destruir_persona(persona_t *persona);
void imprimir_persona(const persona_t *persona);crear_persona: Debe reservar memoria para la estructura y para las cadenas de nombre y apellido (copiándolas).destruir_persona: Debe liberar toda la memoria asociada, incluyendo las cadenas internas.imprimir_persona: Debe mostrar los datos de la persona.
Recordá seguir el principio de simetría (Regla 0x001Ah: Liberá siempre la memoria dinámica y prevení punteros colgantes) y verificar todas las asignaciones de memoria.
```{solution} ej-memoria-estructura
:class: dropdown
```c
#include <stdio.h>
#include <stdlib.h>
typedef struct
{
char *nombre;
char *apellido;
int edad;
} persona_t;
/**
* Calcula la longitud de una cadena.
* @param cadena Cadena a medir (no debe ser NULL).
* @returns La longitud de la cadena (sin contar el '\0').
*/
size_t longitud_cadena(const char *cadena)
{
size_t longitud = 0;
while (cadena[longitud] != '\0')
{
longitud = longitud + 1;
}
return longitud;
}
/**
* Duplica una cadena en memoria dinámica.
* @param cadena Cadena a duplicar (no debe ser NULL).
* @returns Un puntero a la copia, o NULL si hay un error.
*/
char *duplicar_cadena(const char *cadena)
{
if (cadena == NULL)
{
return NULL;
}
size_t longitud = longitud_cadena(cadena);
char *copia = malloc((longitud + 1) * sizeof(*copia));
if (copia == NULL)
{
return NULL;
}
for (size_t i = 0; i <= longitud; i++)
{
copia[i] = cadena[i];
}
return copia;
}
/**
* Crea una nueva persona.
* @param nombre Nombre de la persona (no debe ser NULL).
* @param apellido Apellido de la persona (no debe ser NULL).
* @param edad Edad de la persona.
* @returns Un puntero a la persona creada. El llamador es responsable
* de liberar esta memoria con destruir_persona().
* Retorna NULL si hay un error.
*/
persona_t *crear_persona(const char *nombre, const char *apellido, int edad)
{
if (nombre == NULL || apellido == NULL)
{
return NULL;
}
persona_t *persona = malloc(sizeof(*persona));
if (persona == NULL)
{
return NULL;
}
persona->nombre = duplicar_cadena(nombre);
if (persona->nombre == NULL)
{
free(persona);
return NULL;
}
persona->apellido = duplicar_cadena(apellido);
if (persona->apellido == NULL)
{
free(persona->nombre);
free(persona);
return NULL;
}
persona->edad = edad;
return persona;
}
/**
* Destruye una persona y libera toda su memoria.
* @param persona Puntero a la persona a destruir. Puede ser NULL.
*/
void destruir_persona(persona_t *persona)
{
if (persona != NULL)
{
if (persona->nombre != NULL)
{
free(persona->nombre);
}
if (persona->apellido != NULL)
{
free(persona->apellido);
}
free(persona);
}
}
/**
* Imprime los datos de una persona.
* @param persona Puntero a la persona (no debe ser NULL).
*/
void imprimir_persona(const persona_t *persona)
{
if (persona == NULL)
{
return;
}
printf("Nombre: %s %s\n", persona->nombre, persona->apellido);
printf("Edad: %d años\n", persona->edad);
}
int main()
{
persona_t *p1 = crear_persona("Juan", "Pérez", 30);
if (p1 == NULL)
{
fprintf(stderr, "Error: No se pudo crear la persona.\n");
return 1;
}
imprimir_persona(p1);
destruir_persona(p1);
return 0;
}
```{exercise} Detección de Errores de Memoria
:label: ej-memoria-errores
El siguiente programa contiene varios errores relacionados con la gestión de memoria. Identificá todos los errores, explicá por qué son problemáticos, y corregílos.
```c
#include <stdio.h>
#include <stdlib.h>
int *crear_arreglo(int tamano)
{
int *arr = malloc(tamano * sizeof(int));
for (int i = 0; i <= tamano; i++)
{
arr[i] = i;
}
return arr;
}
void procesar_arreglo(int *arr, int tamano)
{
free(arr);
printf("Procesando arreglo...\n");
for (int i = 0; i < tamano; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
int main()
{
int *numeros = crear_arreglo(5);
procesar_arreglo(numeros, 5);
int valor = numeros[0];
printf("Primer valor: %d\n", valor);
free(numeros);
return 0;
}
```{solution} ej-memoria-errores
:class: dropdown
**Errores identificados:**
1. **En `crear_arreglo`:** No se verifica si `malloc` retornó `NULL`.
2. **En `crear_arreglo`:** Acceso fuera de límites en el lazo (`i <= tamano` debería ser `i < tamano`).
3. **En `crear_arreglo`:** Falta usar `sizeof(*arr)` en lugar de `sizeof(int)` para mayor robustez.
4. **En `crear_arreglo`:** Se debería usar `size_t` para `tamano` en lugar de `int`.
5. **En `procesar_arreglo`:** Se libera la memoria al principio y luego se intenta acceder a ella (uso después de `free`).
6. **En `main`:** Se accede a `numeros` después de que fue liberado en `procesar_arreglo` (puntero colgante).
7. **En `main`:** Doble liberación: se llama a `free(numeros)` dos veces (una en `procesar_arreglo` y otra en `main`).
8. **En `main`:** No se establece `numeros = NULL` después de liberar.
**Código corregido:**
```c
#include <stdio.h>
#include <stdlib.h>
/**
* Crea un arreglo dinámico inicializado con valores secuenciales.
* @param tamano Tamaño del arreglo (debe ser mayor que 0).
* @returns Un puntero al arreglo creado, o NULL si hay un error.
*/
int *crear_arreglo(size_t tamano)
{
if (tamano == 0)
{
return NULL;
}
int *arr = malloc(tamano * sizeof(*arr));
if (arr == NULL)
{
return NULL;
}
for (size_t i = 0; i < tamano; i++)
{
arr[i] = (int)i;
}
return arr;
}
/**
* Procesa un arreglo imprimiendo sus elementos.
* @param arr Puntero al arreglo (no debe ser NULL).
* @param tamano Tamaño del arreglo.
*/
void procesar_arreglo(const int *arr, size_t tamano)
{
if (arr == NULL)
{
return;
}
printf("Procesando arreglo...\n");
for (size_t i = 0; i < tamano; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
int main()
{
size_t tamano = 5;
int *numeros = crear_arreglo(tamano);
if (numeros == NULL)
{
fprintf(stderr, "Error: No se pudo crear el arreglo.\n");
return 1;
}
procesar_arreglo(numeros, tamano);
int valor = numeros[0];
printf("Primer valor: %d\n", valor);
free(numeros);
numeros = NULL;
return 0;
}Cambios realizados:
Se agregó verificación de
malloc.Se corrigió el lazo para evitar acceso fuera de límites.
Se cambió
intporsize_tpara tamaños.Se usó
sizeof(*arr)en lugar desizeof(int).Se removió el
freedeprocesar_arreglo(violaba el principio de responsabilidad única).Se marcó el parámetro de
procesar_arreglocomoconstpara indicar que no modifica el arreglo.Se agregó
numeros = NULLdespués de liberar.Se agregó verificación de que
numerosno esNULLantes de usarlo.
Solution to Exercise 2
#include <stdio.h>
#include <stdlib.h>
/**
* Crea una matriz dinámica contígua usando puntero a array.
* @param filas Número de filas.
* @param columnas Número de columnas.
* @returns Un puntero a array que apunta a la matriz, o NULL si hay error.
* @note Requiere C99+ para VLA en tipo de retorno.
*/
int (*crear_matriz_contigua(size_t filas, size_t columnas))[columnas]
{
// Asignar memoria contígua para todos los elementos
int (*matriz)[columnas] = malloc(filas * sizeof(*matriz));
if (matriz == NULL)
{
return NULL;
}
// Inicializar a cero
for (size_t i = 0; i < filas; i++)
{
for (size_t j = 0; j < columnas; j++)
{
matriz[i][j] = 0;
}
}
return matriz;
}
/**
* Llena la matriz con el patrón: matriz[i][j] = i * columnas + j
* @param matriz Puntero a la matriz (no debe ser NULL).
* @param filas Número de filas.
* @param columnas Número de columnas.
*/
void llenar_matriz(int (*matriz)[/* columnas debe coincidir */],
size_t filas, size_t columnas)
{
if (matriz == NULL)
{
return;
}
for (size_t i = 0; i < filas; i++)
{
for (size_t j = 0; j < columnas; j++)
{
matriz[i][j] = (int)(i * columnas + j);
}
}
}
/**
* Imprime la matriz.
* @param matriz Puntero a la matriz (no debe ser NULL).
* @param filas Número de filas.
* @param columnas Número de columnas.
*/
void imprimir_matriz_contigua(int (*matriz)[], size_t filas, size_t columnas)
{
if (matriz == NULL)
{
return;
}
for (size_t i = 0; i < filas; i++)
{
for (size_t j = 0; j < columnas; j++)
{
// Acceso usando puntero a array
printf("%4d ", (*matriz)[i * columnas + j]);
}
printf("\n");
}
}
/**
* Transpone una matriz cuadrada in-place.
* @param matriz Puntero a la matriz cuadrada (no debe ser NULL).
* @param n Tamaño de la matriz (n×n).
*/
void transponer_cuadrada(int (*matriz)[/* n */], size_t n)
{
if (matriz == NULL)
{
return;
}
// Intercambiar matriz[i][j] con matriz[j][i]
for (size_t i = 0; i < n; i++)
{
for (size_t j = i + 1; j < n; j++)
{
int temp = matriz[i][j];
matriz[i][j] = matriz[j][i];
matriz[j][i] = temp;
}
}
}
int main()
{
size_t n = 4; // Matriz 4×4
// Crear matriz contígua
int (*matriz)[n] = crear_matriz_contigua(n, n);
if (matriz == NULL)
{
fprintf(stderr, "Error: No se pudo crear la matriz.\n");
return 1;
}
// Llenar con patrón
llenar_matriz((int (*)[])(matriz), n, n);
printf("Matriz original %zu×%zu:\n", n, n);
imprimir_matriz_contigua((int (*)[])(matriz), n, n);
// Transponer
transponer_cuadrada((int (*)[])(matriz), n);
printf("\nMatriz transpuesta:\n");
imprimir_matriz_contigua((int (*)[])(matriz), n, n);
// Verificar la transposición
printf("\nVerificación:\n");
printf("Elemento [0][1] (era 1, ahora debe ser 4): %d\n", matriz[0][1]);
printf("Elemento [1][0] (era 4, ahora debe ser 1): %d\n", matriz[1][0]);
printf("Elemento [2][3] (era 11, ahora debe ser 14): %d\n", matriz[2][3]);
// Liberar: una sola llamada
free(matriz);
matriz = NULL;
return 0;
}Explicación de puntos clave:
Un solo malloc/free: Toda la memoria se asigna contígua, mejorando la localidad del caché.
Sintaxis de puntero a array:
int (*matriz)[columnas]permite acceder conmatriz[i][j]naturalmente.VLA en tipo de retorno: Necesitás C99+ para que
columnassea parte del tipo de retorno.Transposición in-place: Solo intercambia elementos por encima de la diagonal, evitando intercambios dobles.
Casteos: Para funciones que toman
int (*matriz)[](tamaño desconocido), necesitás castear desdeint (*matriz)[n].
Alternativa sin VLA (más portable):
Si tu compilador no soporta VLAs en tipos de retorno, podés usar un typedef con tamaño fijo o trabajar con void *:
// Opción 1: Tamaño fijo con typedef
#define MAX_COLS 10
typedef int fila_t[MAX_COLS];
fila_t *crear_matriz_fija(size_t filas)
{
return malloc(filas * sizeof(fila_t));
}
// Opción 2: void * y casteo manual
void *crear_matriz_generica(size_t filas, size_t cols)
{
return malloc(filas * cols * sizeof(int));
}
// Uso:
int (*matriz)[4] = (int (*)[4])crear_matriz_generica(5, 4);Conceptos Avanzados¶
Jerarquía de Memoria y Caché¶
Para comprender completamente por qué el stack es más rápido que el heap, necesitás entender la jerarquía de memoria del hardware moderno. La memoria no es un espacio uniforme: hay múltiples niveles con diferentes velocidades y tamaños.
La jerarquía típica (de más rápido a más lento):

Figure 10:Jerarquía de memoria desde los registros CPU (más rápidos) hasta los discos duros (más lentos), mostrando la relación inversa entre velocidad y capacidad.
Principio de localidad:
El hardware moderno optimiza para dos tipos de localidad:
Localidad temporal: Si accedés a un dato ahora, es probable que lo accedas de nuevo pronto.
Localidad espacial: Si accedés a un dato, es probable que accedas a datos cercanos en memoria pronto.
Cómo funcionan los cachés:
Cuando el CPU necesita leer memoria, primero busca en el caché L1. Si no está (cache miss), busca en L2, luego L3, y finalmente en RAM. Cuando encuentra el dato, también trae a caché los bytes circundantes (una “línea de caché”, típicamente 64 bytes).
Acceso a memoria:
CPU → L1? (hit) → Usar dato (rápido)
↓ (miss)
L2? (hit) → Copiar a L1 → Usar dato
↓ (miss)
L3? (hit) → Copiar a L2 y L1 → Usar dato
↓ (miss)
RAM → Copiar a cachés → Usar dato (lento)Por qué el stack es más rápido:
Alta localidad temporal: Las variables locales se usan frecuentemente en un corto período (dentro de la función). Probablemente permanecen en caché.
Alta localidad espacial: Las variables locales están físicamente juntas en memoria. Acceder a una trae las otras al caché automáticamente.
Patrón predecible: El stack crece y decrece de forma predecible, lo que permite al hardware pre-cargar datos.
Acceso secuencial: Generalmente accedés a variables locales en orden, lo que maximiza el uso de las líneas de caché.
Por qué el heap es más lento:
Menor localidad: Las asignaciones de memoria pueden estar dispersas por todo el heap, causando más cache misses.
Indirección: Acceder a memoria del heap requiere desreferenciar punteros, agregando un nivel de indirección.
Fragmentación: Los bloques fragmentados están físicamente separados, reduciendo la localidad espacial.
Overhead del allocator: Cada
malloc/freeinvolucra algoritmos de búsqueda y mantenimiento de estructuras de datos.
Ejemplo cuantitativo:
// Versión stack (rápida):
void procesar_stack()
{
int datos[1000]; // Asignación instantánea
// Todos los elementos probablemente en caché:
for (int i = 0; i < 1000; i++)
{
datos[i] = i * 2; // Acceso secuencial, alta localidad
}
}
// Versión heap (más lenta):
void procesar_heap()
{
int *datos = malloc(1000 * sizeof(int)); // Llamada a función
if (datos == NULL) return;
// Posiblemente más cache misses:
for (int i = 0; i < 1000; i++)
{
datos[i] = i * 2; // Menos predecible para el hardware
}
free(datos); // Otra llamada a función
}En un benchmark real, la versión stack podría ser 2-5 veces más rápida, especialmente para arreglos pequeños que caben completamente en caché.
Fragmentación de Memoria¶
La fragmentación es un fenómeno que ocurre cuando el heap contiene bloques libres pequeños dispersos que no pueden satisfacer solicitudes de memoria más grandes, incluso si la suma total de memoria libre sería suficiente.
Imaginá que tenés un estante con espacios libres dispersos de diferentes tamaños. Aunque la suma total de espacio libre sea grande, si necesitás colocar un libro grande y solo tenés espacios pequeños separados, no podrás hacerlo. Lo mismo ocurre con la memoria.
Fragmentación Externa: Espacios libres entre bloques asignados que son demasiado pequeños para ser útiles individualmente. Ocurre cuando asignás y liberás bloques de memoria de diferentes tamaños en un orden arbitrario, dejando “huecos” entre bloques ocupados.
Ejemplo conceptual:

Figure 11:Proceso de fragmentación externa: se asignan tres bloques (A, B, C), luego se libera B dejando un hueco. Ahora hay dos bloques libres separados, pero ninguno puede satisfacer una solicitud del tamaño de A+B.
Ahora hay dos bloques libres, pero si necesitás un bloque del tamaño de A+B, no podés usar el espacio libre entre A y C.
Fragmentación Interna: Desperdicio de memoria dentro de un bloque asignado cuando se solicita menos de lo que el sistema asigna. Algunos sistemas asignan memoria en múltiplos de cierto tamaño (por ejemplo, bloques de 16 bytes), entonces si pedís 10 bytes, te dan 16 y los 6 extra se desperdician.
Cómo minimizar la fragmentación:
Liberá memoria en el orden inverso al que la asignaste cuando sea posible.
Usá tamaños consistentes para asignaciones frecuentes.
Considerá usar memory pools para objetos de tamaño fijo (tema avanzado).
Alineación de Memoria¶
La alineación de memoria es un concepto fundamental que afecta tanto el rendimiento como la corrección de los programas. Comprender por qué existe y cómo funciona te permite escribir código más eficiente.
¿Qué es la alineación?
Un dato está alineado cuando su dirección de memoria es un múltiplo de su tamaño. Por ejemplo:
Un
char(1 byte) puede estar en cualquier dirección.Un
short(2 bytes) debería estar en direcciones múltiplo de 2.Un
int(4 bytes) debería estar en direcciones múltiplo de 4.Un
double(8 bytes) debería estar en direcciones múltiplo de 8.

Figure 12:Comparación entre memoria bien alineada (donde cada int comienza en un múltiplo de 4) y mal alineada (causando penalización de rendimiento). El acceso alineado requiere una sola lectura del CPU, mientras que el desalineado requiere múltiples lecturas y manipulación de bits.
¿Por qué importa la alineación?
Los procesadores modernos leen memoria en bloques (palabras) de tamaño fijo, típicamente 4 u 8 bytes a la vez. Si un dato no está alineado:
Penalización de rendimiento: El CPU debe hacer múltiples lecturas y combinarlas con operaciones de bits. Una lectura alineada toma 1 operación, mientras que una desalineada puede tomar 2 operaciones más manipulación adicional (2-3x más lento).
En algunas arquitecturas, causa errores: ARM en modo estricto y algunos procesadores RISC generan excepciones de alineación.
Operaciones atómicas: Muchas instrucciones atómicas (necesarias para multithreading) requieren alineación natural.
Alineación en estructuras:
El compilador inserta “padding” (bytes de relleno) para mantener la alineación:
struct ejemplo {
char a; // 1 byte
// 3 bytes de padding insertados automáticamente
int b; // 4 bytes (debe estar en múltiplo de 4)
char c; // 1 byte
// 3 bytes de padding al final para el arreglo
};
// sizeof(struct ejemplo) = 12, no 6Visualización:

Figure 13:Comparación entre una estructura sin padding (incorrecta con desalineación) y con padding (correcta con alineación apropiada). El compilador inserta bytes de relleno para mantener la alineación de los campos.
Optimizar estructuras:
Podés minimizar el padding ordenando los campos de mayor a menor:
// Desperdicia espacio (16 bytes):
struct ineficiente {
char a; // 1 byte
int b; // 4 bytes (+ 3 padding antes)
char c; // 1 byte (+ 3 padding después)
};
// Más eficiente (8 bytes):
struct eficiente {
int b; // 4 bytes
char a; // 1 byte
char c; // 1 byte
// 2 bytes padding al final (menos que antes)
};Verificar alineación:
#include <stdio.h>
#include <stddef.h>
struct prueba {
char a;
int b;
char c;
};
int main()
{
printf("Tamaño de struct: %zu\n", sizeof(struct prueba));
printf("Offset de 'a': %zu\n", offsetof(struct prueba, a));
printf("Offset de 'b': %zu\n", offsetof(struct prueba, b));
printf("Offset de 'c': %zu\n", offsetof(struct prueba, c));
return 0;
}malloc y alineación:
Las funciones de asignación de memoria (malloc y calloc) garantizan que la memoria devuelta está adecuadamente alineada para cualquier tipo de dato estándar. Típicamente retornan direcciones alineadas a 8 o 16 bytes, lo cual satisface los requisitos de todos los tipos básicos.
int *p = malloc(sizeof(int));
// p está garantizado como alineado para 'int'
struct grande {
double d; // Necesita alineación de 8 bytes
long l;
};
struct grande *s = malloc(sizeof(*s));
// s está garantizado como alineado para todos los camposHerramientas de Depuración: Valgrind¶
Valgrind es una herramienta fundamental para detectar errores de memoria en programas C y C++. Funciona ejecutando tu programa en un entorno virtualizado donde puede monitorear cada acceso a memoria y operación de asignación/liberación.
Tipos de errores que detecta:
Fugas de memoria (memory leaks): Bloques de memoria asignados que nunca fueron liberados.
Accesos a memoria no inicializada: Leer valores de memoria que nunca fueron escritos.
Accesos fuera de límites: Leer o escribir más allá de los límites de un bloque asignado.
Dobles liberaciones: Intentar liberar el mismo bloque dos veces.
Uso de memoria después de
free: Acceder a memoria que ya fue liberada.Desajustes entre asignación y liberación: Por ejemplo, asignar con
mallocy liberar condelete(en C++).
Uso básico:
# Compilar con símbolos de depuración
gcc -g -o programa programa.c
# Ejecutar con Valgrind
valgrind --leak-check=full --show-leak-kinds=all ./programaOpciones útiles:
--leak-check=full: Muestra detalles completos de las fugas de memoria.--show-leak-kinds=all: Muestra todos los tipos de fugas.--track-origins=yes: Rastrea el origen de valores no inicializados (más lento pero útil).--verbose: Muestra información adicional de depuración.
Interpretando la salida:
Cuando Valgrind detecta un error, muestra:
El tipo de error
La ubicación en el código (archivo y línea)
El stack trace (secuencia de llamadas que llevó al error)
Para fugas de memoria: dónde se asignó el bloque que no fue liberado
Ejemplo de salida:
==12345== Invalid write of size 4
==12345== at 0x108A: main (programa.c:15)
==12345== Address 0x522d068 is 0 bytes after a block of size 40 alloc'dEsto indica que se intentó escribir 4 bytes fuera de un bloque de 40 bytes asignado, en la línea 15 del archivo programa.c.
Modelo de Costos: Cuantificando el Rendimiento¶
Comprender el costo relativo de las operaciones de memoria te permite tomar decisiones informadas sobre diseño y optimización. Este modelo proporciona una intuición sobre el rendimiento relativo.
Costos relativos (ciclos de CPU aproximados):
Si un acceso a registro tomara 1 segundo, acceder a RAM tomaría entre 2 y 5 minutos, y leer del disco duro tomaría 4 meses. Esta escala ayuda a visualizar la enorme diferencia de velocidades.
| Operación | Ciclos aprox. | Equivalente temporal |
|---|---|---|
| Acceso a registro | 1 | 1 segundo |
| Acceso a L1 cache | 4 | 4 segundos |
| Acceso a L2 cache | 12 | 12 segundos |
| Acceso a L3 cache | 40 | 40 segundos |
| Acceso a RAM | 100-300 | 2-5 minutos |
| malloc pequeño (heap hit) | 50-100 | 1-2 minutos |
| malloc grande (new pages) | 1,000-10,000 | 15 minutos - 3 horas |
| free (simple) | 20-50 | 20-50 segundos |
| Fallo de página (page fault) | 10,000-100,000 | 3 horas - 1 día |
| Acceso a SSD | 100,000 | 1 día |
| Acceso a disco HDD | 10,000,000 | 4 meses |
Implicaciones prácticas:
1. Las asignaciones no son gratuitas:
// Ineficiente: muchas asignaciones pequeñas
for (int i = 0; i < 1000; i++)
{
char *str = malloc(10); // 1000 llamadas a malloc
// ... usar str ...
free(str); // 1000 llamadas a free
}
// Mejor: una asignación grande
char *buffer = malloc(10000);
for (int i = 0; i < 1000; i++)
{
char *str = buffer + (i * 10); // Solo aritmética de punteros
// ... usar str ...
}
free(buffer); // Una sola llamada a freeLa segunda versión puede ser 10-100 veces más rápida.
2. La localidad de acceso importa enormemente:
// Malo: Acceso aleatorio (muchos cache misses)
for (int i = 0; i < n; i++)
{
int idx = random_index();
data[idx] = process(data[idx]); // Impredecible para el caché
}
// Bueno: Acceso secuencial (cache hits)
for (int i = 0; i < n; i++)
{
data[i] = process(data[i]); // Predecible, alta localidad
}3. El tamaño de la estructura de datos importa:
// Si tu estructura cabe en caché L1 (32 KB):
struct pequena datos[1000]; // 4 KB total, cabe en L1
// Acceso muy rápido, todo en caché
// Si excede la caché L3 (8 MB):
struct grande datos[1000000]; // 100 MB, no cabe
// Muchos accesos a RAM, más lento4. El costo de la indirección:
// Un nivel de indirección:
int *ptr = malloc(sizeof(int));
*ptr = 42; // Lee ptr, luego lee *ptr (2 accesos potenciales a RAM)
// Dos niveles de indirección:
int **ptr2 = malloc(sizeof(int *));
*ptr2 = malloc(sizeof(int));
**ptr2 = 42; // Lee ptr2, luego *ptr2, luego **ptr2 (3 accesos)
// Directo (sin indirección):
int valor = 42; // Puede estar en registro, cero accesos a memoriaEjemplo cuantitativo:
Considerá procesar un millón de elementos:
// Opción A: Arreglo continuo (stack o heap)
int arreglo[1000000];
for (int i = 0; i < 1000000; i++)
{
arreglo[i] = i * 2;
}
// Costo: ~1 millón de escrituras secuenciales
// Cache: Muy efectivo (prefetching automático)
// Tiempo: ~1-2 ms en un CPU moderno
// Opción B: Lista enlazada (heap)
struct nodo *lista = crear_lista(1000000);
struct nodo *actual = lista;
int i = 0;
while (actual != NULL)
{
actual->valor = i * 2;
actual = actual->siguiente; // Sigue puntero (indirección)
i++;
}
// Costo: ~1 millón de escrituras + 1 millón de lecturas de punteros
// Cache: Malo (los nodos están dispersos)
// Tiempo: ~5-20 ms (3-10x más lento)Estrategias de optimización basadas en el modelo de costos:
Minimizá asignaciones dinámicas: Usá stack cuando sea posible, o pooling de memoria.
Maximizá localidad: Mantené datos relacionados físicamente juntos.
Reducí indirección: Preferí arreglos sobre listas enlazadas cuando el acceso aleatorio es importante.
Batch operations: Procesá múltiples elementos antes de saltar a otra región de memoria.
Considerá el cache line size: Operá en bloques de ~64 bytes cuando sea posible.
Conclusiones¶
La gestión de memoria dinámica es una de las características más poderosas y peligrosas de C. Su dominio requiere comprender no solo las funciones y sintaxis, sino también los principios fundamentales de cómo funciona la memoria en un programa.
Las buenas prácticas presentadas en este apunte no son sugerencias opcionales: son requisitos para escribir código C profesional y confiable. Cada regla existe porque previene errores reales que han causado innumerables problemas en sistemas de producción.
A medida que adquirás experiencia, estas prácticas se vuelven segunda naturaleza. Inicialmente pueden parecer restrictivas, pero con el tiempo reconocerás que son liberadoras: te permiten escribir código complejo con confianza, sabiendo que has evitado las trampas más comunes.
Referencias y Lecturas Adicionales¶
Para profundizar en la gestión de memoria, consultá:
The C Programming Language, Kernighan & Ritchie (Capítulo 5: Punteros y Arreglos)
C Programming: A Modern Approach, K. N. King (Capítulo 17: Memoria Dinámica)
Modern C, Jens Gustedt (Nivel 2: Cognición)
Para las reglas de estilo, consultá el documento Regla 0x0000h: La claridad y prolijidad son de máxima importancia donde se detallan todas las convenciones utilizadas en este curso.
Conceptos Clave¶
Este apunte explora la gestión de memoria dinámica, el mecanismo que permite a los programas solicitar y liberar memoria durante la ejecución, habilitando estructuras de datos flexibles y adaptables.
Conexión con el Siguiente Tema¶
Con memoria dinámica dominada, tenemos las herramientas para implementar cualquier estructura de datos. Pero antes de construir estructuras complejas, necesitamos entender cómo medir su eficiencia: ¿cuánto tiempo toma buscar un elemento? ¿Cómo crece el tiempo de ejecución al duplicar el tamaño de entrada?
El apunte Introducción: El Estudio de la Eficiencia introduce el análisis asintótico de algoritmos:
Notación Big-O, Omega, Theta para caracterizar crecimiento
Análisis de lazos, recursión, y algoritmos complejos
Jerarquía de complejidades:
Trade-offs entre tiempo y espacio
El análisis de complejidad es fundamental para tomar decisiones informadas: ¿vale la pena usar una lista enlazada (memoria dinámica, búsqueda) o un arreglo redimensionable (overhead de copia, acceso)? Sin complejidad, solo podemos intuir; con ella, podemos demostrar matemáticamente qué solución es mejor.
Después, el apunte Tipos de Datos Abstractos, Pilas y Colas muestra cómo encapsular estructuras con memoria dinámica en Tipos Abstractos de Datos, ocultando detalles de implementación y exponiendo interfaces limpias.
Pregunta puente: Una búsqueda lineal en lista enlazada toma tiempo. ¿Podemos hacer mejor? ¿Cómo cuantificamos “mejor”? La respuesta requiere análisis formal de complejidad algorítmica.